Guest post by Dillon Franke, Senior Security Engineer, 20% time on Project Zero
Every second, highly-privileged MacOS system daemons accept and process hundreds of IPC messages. In some cases, these message handlers accept data from sandboxed or unprivileged processes.
In this blog post, I’ll explore using Mach IPC messages as an attack vector to find and exploit sandbox escapes. I’ll detail how I used a custom fuzzing harness, dynamic instrumentation, and plenty of debugging/static analysis to identify a high-risk type confusion vulnerability in the coreaudiod system daemon. Along the way, I’ll discuss some of the difficulties and tradeoffs I encountered.
Transparently, this was my first venture into the world of MacOS security research and building a custom fuzzing harness. I hope this post serves as a guide to those who wish to embark on similar research endeavors.
I am open-sourcing the fuzzing harness I built, as well as several tools I wrote that were useful to me throughout this project. All of this can be found here: https://github.com/googleprojectzero/p0tools/tree/master/CoreAudioFuzz
The Approach: Knowledge-Driven Fuzzing
For this research project, I adopted a hybrid approach that combined fuzzing and manual reverse engineering, which I refer to as knowledge-driven fuzzing. This method, learned from my friend Ned Williamson, balances automation with targeted investigation. Fuzzing provided the means to quickly test a wide range of inputs and identify areas where the system’s behavior deviated from expectations. However, when the fuzzer’s code coverage plateaued or specific hurdles arose, manual analysis came into play, forcing me to dive deeper into the target’s inner workings.
Knowledge-driven fuzzing offers two key advantages. First, the research process never stagnates, as the goal of improving the code coverage of the fuzzer is always present. Second, achieving this goal requires a deep understanding of the code you are fuzzing. By the time you begin triaging legitimate, security-relevant crashes, the reverse engineering process will have given you extensive knowledge of the codebase, enabling analysis of crashes from an informed perspective.
The cycle I followed during this research is as follows:
- Identify an attack vector
- Choose a target
- Create a fuzzing harness
- Fuzz and produce crashes
- Analyze crashes and code coverage
- Iterate on the fuzzing harness
- Repeat steps 4-6
Identify an Attack Vector
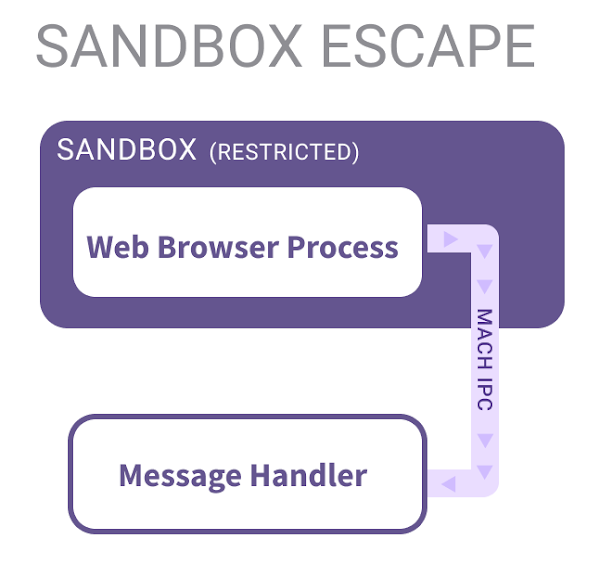
Standard browser sandboxing limits code execution by restricting direct operating system access. Consequently, exploiting a browser vulnerability typically requires the use of a separate “sandbox escape” vulnerability.
Since interprocess communication (IPC) mechanisms allow two processes to communicate with each other, they can naturally serve as a bridge from a sandboxed process to an unrestricted one. This makes them a prime attack vector for sandbox escapes, as shown below.

I chose Mach messages, the lowest level IPC component in the MacOS operating system, as the attack vector of focus for this research. I chose them mostly due to my desire to understand MacOS IPC mechanisms at their most core level, as well as the track record of historical security issues with Mach messages.
Previous Work and Background
Leveraging Mach messages in exploit chains is far from a novel idea. For example, Ian Beer identified a core design issue in 2016 with the XNU kernel related to the handling of task_t Mach ports, which allowed for exploitation via Mach messages. Another post showed how an in-the-wild exploit chain utilized Mach messages in 2019 for heap grooming techniques. I also drew much inspiration from Ret2 Systems’ blog post about leveraging Mach message handlers to find and weaponize a Safari sandbox escape.
I won’t spend too much time detailing the ins and outs of how Mach messages work, (that is better left to a more comprehensive post on the subject) but here’s a brief overview of Mach IPC for this blog post:
- Mach messages are stored within kernel-managed message queues, represented by a Mach port
- A process can fetch a message from a given port if it holds the receive right for that port
- A process can send a message to a given port if it holds a send right to that port
MacOS applications can register a service with the bootstrap server, a special mach port which all processes have a send right to by default. This allows other processes to send a Mach message to the bootstrap server inquiring about a specific service, and the bootstrap server can respond with a send right to that service’s Mach port. MacOS system daemons register Mach services via launchd. You can view their .plist files within the /System/Library/LaunchAgents and /System/Library/LaunchDaemons directories to get an idea of the services registered. For example, the .plist file below highlights a Mach service registered for the Address Book application on MacOS using the identifier com.apple.AddressBook.AssistantService.
<?xml version=”1.0″ encoding=”UTF-8″?>
<!DOCTYPE plist PUBLIC “-//Apple//DTD PLIST 1.0//EN” “http://www.apple.com/DTDs/PropertyList-1.0.dtd”>
<plist version=”1.0″>
<dict>
<key>POSIXSpawnType</key>
<string>Adaptive</string>
<key>Label</key>
<string>com.apple.AddressBook.AssistantService</string>
<key>MachServices</key>
<dict>
<key>com.apple.AddressBook.AssistantService</key>
<true/>
</dict>
<key>ProgramArguments</key>
<array>
<string>/System/Library/Frameworks/AddressBook.framework/Versions/A/Helpers/ABAssistantService.app/Contents/MacOS/ABAssistantService</string>
</array>
</dict>
</plist>
Choose a Target
After deciding I wanted to research Mach services, the next question was which service to target. In order for a sandboxed process to send Mach messages to a service, it has to be explicitly allowed. If the process is using Apple’s App Sandbox feature, this is done within a .sb file, written using the TinyScheme format. The snippet below shows an excerpt of the sandbox file for a WebKit GPU Process. The allow mach-lookup directive is used to allow a sandboxed process to lookup and send Mach messages to a service.
# File: /System/Volumes/Preboot/Cryptexes/Incoming/OS/System/Library/Frameworks/WebKit.framework/Versions/A/Resources/com.apple.WebKit.GPUProcess.sb
(with-filter (system-attribute apple-internal)
(allow mach-lookup
(global-name “com.apple.analyticsd”)
(global-name “com.apple.diagnosticd”)))
(allow mach-lookup
(global-name “com.apple.audio.audiohald”)
(global-name “com.apple.CARenderServer”)
(global-name “com.apple.fonts”)
(global-name “com.apple.PowerManagement.control”)
(global-name “com.apple.trustd.agent”)
(global-name “com.apple.logd.events”))
This helped me narrow my focus significantly from all MacOS processes, to processes with a sandbox-accessible Mach service:

In addition to inspecting the sandbox profiles, I used Jonathan Levin’s sbtool utility to test which Mach services could be interacted with for a given process. The tool (which was a bit outdated, but I was able to get it to compile) uses the builtin sandbox_exec function under the hood to provide a nice list of accessible Mach service identifiers:
❯ ./sbtool 2813 mach
com.apple.logd
com.apple.xpc.smd
com.apple.remoted
com.apple.metadata.mds
com.apple.coreduetd
com.apple.apsd
com.apple.coreservices.launchservicesd
com.apple.bsd.dirhelper
com.apple.logind
com.apple.revision
…Truncated…
Ultimately, I chose to take a look at the coreaudiod daemon, and specifically the com.apple.audio.audiohald service for the following reasons:
- It is a complex process
- It allows Mach communications from several impactful applications, including the Safari GPU process
- The Mach service had a large number of message handlers
- The service seemed to allow control and and modification of audio hardware, which would likely require elevated privileges
- The coreaudiod binary and the CoreAudio Framework it heavily uses were both closed source, which would provide a unique reverse engineering challenge
Create a Fuzzing Harness
Once I chose an attack vector and target, the next step was to create a fuzzing harness capable of sending input through the attack vector (a Mach message) at a proper location within the target.
A coverage-guided fuzzer is a powerful weapon, but only if its energy is focused in the right place—like a magnifying glass concentrating sunlight to start a fire. Without proper focus, the energy dissipates, achieving little impact.
Determining an Entry Point
Ideally, a fuzzer should perfectly replicate the environment and capabilities available to a potential attacker. However, this isn’t always practical. Trade-offs often need to be made, such as accepting a higher rate of false positives for increased performance, simplified instrumentation, or ease of development. Therefore, identifying the “right place” to fuzz is highly dependent on the specific target and research goals.
Option 1: Interprocess Fuzzing
All Mach messages are sent and received using the mach_msg API, as shown below. Therefore, I thought the most intuitive way to fuzz coreaudiod‘s Mach message handlers would be to write a fuzzing harness that called the mach_msg API and allow my fuzzer to modify the message contents to produce crashes. The approach would look something like this:

However, this approach had a large downside: since we were sending IPC messages, the fuzzing harness would be in a different process space than the target. This meant code coverage information would need to be shared across a process boundary, which is not supported by most fuzzing tools. Additionally, kernel message queue processing adds a significant performance overhead.
Option 2: Direct Harness
While requiring a bit more work up front, another option was to write a fuzzing harness that directly loaded and called the Mach message handlers of interest. This would have the massive advantage of putting our fuzzer and instrumentation in the same process as the message handlers, allowing us to more easily obtain code coverage.

One notable downside of this fuzzing approach is that it assumes all fuzzer-generated inputs pass the kernel’s Mach message validation layer, which in a real system occurs before a message handler gets called. As we’ll see later, this is not always the case. In my view, however, the pros of fuzzing in the same process space (speed and easy code coverage collection) outweighed the cons of a potential increase in false positives.
The approach would be as follows:
- Identify a suitable function for processing incoming mach messages
- Write a fuzzing harness to load the message handling code from coreaudiod
- Use a fuzzer to generate inputs and call the fuzzing harness
- Profit, hopefully
Finding the Mach Messager Handler
To start, I searched for the Mach service identifier, com.apple.audioaudiohald, but found no references to it within the coreaudiod binary. Next, I checked the libraries it loaded using otool. Logically, the CoreAudio framework seemed like a good candidate for housing the code for our message handler.
$ otool -L /usr/sbin/coreaudiod
/usr/sbin/coreaudiod:
/System/Library/PrivateFrameworks/caulk.framework/Versions/A/caulk (compatibility version 1.0.0, current version 1.0.0)
/System/Library/Frameworks/CoreAudio.framework/Versions/A/CoreAudio (compatibility version 1.0.0, current version 1.0.0)
/System/Library/Frameworks/CoreFoundation.framework/Versions/A/CoreFoundation (compatibility version 150.0.0, current version 2602.0.255)
/usr/lib/libAudioStatistics.dylib (compatibility version 1.0.0, current version 1.0.0, weak)
/System/Library/Frameworks/Foundation.framework/Versions/C/Foundation (compatibility version 300.0.0, current version 2602.0.255)
/usr/lib/libobjc.A.dylib (compatibility version 1.0.0, current version 228.0.0)
/usr/lib/libc++.1.dylib (compatibility version 1.0.0, current version 1700.255.5)
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1345.120.2)
However, I was surprised to find that the path returned by otool did not exist!
$ stat /System/Library/Frameworks/CoreAudio.framework/Versions/A/CoreAudio
stat: /System/Library/Frameworks/CoreAudio.framework/Versions/A/CoreAudio: stat: No such file or directory
The Dyld Shared Cache
A bit of research showed me that as of MacOS Big Sur, most framework binaries are not stored on disk but within the dyld shared cache, a mechanism for pre-linking libraries to allow applications to run faster. Thankfully, IDA Pro, Binary Ninja, and Ghidra support parsing the dyld shared cache to obtain the libraries stored within. I also used this helpful tool to successfully extract libraries for additional analysis.
Once I had the CoreAudio Framework within IDA, I quickly found a call to bootstrap_check_in with the service identifier passed as an argument, proving the CoreAudio framework binary was responsible for setting up the Mach service I wanted to fuzz. However, it still wasn’t obvious where the message handling code was happening, despite quite a bit of reverse engineering.

It turns out this is due to the use of the Mach Interface Generator, (MIG) an Interface Definition Language from Apple that makes it easier to write RPC clients and servers by abstracting away much of the Mach layer. When compiled, MIG message handling code gets bundled into a structure called a subsystem. One can easily grep for these subsystems to find their offsets:
$ nm -m ./System/Library/Frameworks/CoreAudio.framework/Versions/A/CoreAudio | grep -i subsystem
(undefined) external _CACentralStateDumpRegisterSubsystem (from AudioToolboxCore)
00007ff840470138 (__DATA_CONST,__const) non-external _HALC_HALB_MIGClient_subsystem
00007ff840470270 (__DATA_CONST,__const) non-external _HALS_HALB_MIGServer_subsystem
Next, I searched in IDA for cross-references to the _HALS_HALB_MIGServer_subsystem symbol, which identified the MIG server function that parsed incoming Mach messages! The routine is shown below, with the first parameter (the rdi register) being the incoming Mach message and the second (the rsi register) being the message to return to the client. The MIG server function extracted the msgh_id parameter from the Mach message and used that to index into the MIG subsystem. Then, the necessary function handler was called.

I further confirmed this by setting an LLDB breakpoint on the coreaudiod process (after disabling SIP) for the _HALB_MIGServer_server function. Then, I adjusted the volume on my system, and the breakpoint was hit:

In this example, tracing the message handler called from the MIG subsystem showed the _XObject_HasProperty function was called based on the Mach message’s msgh_id.

Depending on the msgh_id, a few dozen message handlers were accessible from the MIG subsystem. They are easily identifiable by the convenient __X prefix to their function names added by MIG.

The _HALB_MIGServer_server function struck a great balance between getting close to low-level message handling code while still resembling the inputs that a call to mach_msg would take. I decided this was the place to inject fuzz input into.
Creating a Basic Fuzzing Harness
After identifying the function I wanted to fuzz, the next step was to write a program to read a file and deliver the file’s contents as input to the target function. This might have been as easy as linking the CoreAudio library with my fuzzing harness and calling the _HALB_MIGServer_server function, but unfortunately the function was not exported.
Instead, I borrowed some logic from Ivan Fratric and his TinyInst tool (we’ll be talking about it a lot more later) which returns a provided symbol’s address from a library. The code parses the structure of Mach-O binaries, specifically their headers and load commands, to locate and extract symbol information. This made it possible to resolve and call the target function in my fuzzing harness, even when it wasn’t exported.
So, the high level function of my harness was as follows:
- Load the CoreAudio Library
- Get a function pointer for the target function from the CoreAudio Library
- Read an input from a file
- Call the target function with the input
The full implementation of my fuzzing harness can be found here. An example of invoking the harness to send a message from an input file is shown below:
$ ./harness -f corpora/basic/1 -v
*******NEW MESSAGE*******
Message ID: 1010000 (XSystem_Open)
—— MACH MSG HEADER ——
msg_bits: 2319532353
msg_size: 56
msg_remote_port: 1094795585
msg_local_port: 1094795585
msg_voucher_port: 1094795585
msg_id: 1010000
—— MACH MSG BODY (32 bytes) ——
0x01 0x00 0x00 0x00 0x03 0x30 0x00 0x00 0x41 0x41 0x41 0x41 0x41 0x41 0x11 0x00 0x41 0x41 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
—— MACH MSG TRAILER ——
msg_trailer_type: 0
msg_trailer_size: 32
msg_seqno: 0
msg_sender: 0
—— MACH MSG TRAILER BODY (32 bytes) ——
0xf5 0x01 0x00 0x00 0xf5 0x01 0x00 0x00 0x14 0x00 0x00 0x00 0xf5 0x01 0x00 0x00 0x14 0x00 0x00 0x00 0x7e 0x02 0x00 0x00 0xa3 0x86 0x01 0x00 0x4f 0x06 0x00 0x00
Processing function result: 1
*******RETURN MESSAGE*******
—— MACH MSG HEADER ——
msg_bits: 1
msg_size: 36
msg_remote_port: 1094795585
msg_local_port: 0
msg_voucher_port: 0
msg_id: 1010100
—— MACH MSG BODY (12 bytes) ——
0x00 0x00 0x00 0x00 0x01 0x00 0x00 0x00 0x00 0x00 0x00 0x00
Harvesting Legitimate Mach Messages
I now had a way to deliver data directly into the MIG subsystem (_HALB_MIGServer_server) I wanted to fuzz. However, I had no idea the specific message size, options, or data the handler was expecting. While a coverage-guided fuzzer will begin to uncover the proper message format over time, it is advantageous to obtain a seed corpus of legitimate inputs when first beginning to fuzz to improve efficiency.
To do this, I used LLDB to set a breakpoint on the MIG subsystem and dump the first argument (containing the incoming Mach message). Then, I played around with the operating system to cause Mach messages to be sent to coreaudiod. The Audio MIDI Setup MacOS application ended up being great for this, as it allows one to create, edit, and delete audio devices.

Fuzz and Produce Crashes
Armed with a small seed corpus and an input delivery mechanism, the next step was to configure a fuzzer to use the created fuzzing harness and obtain code coverage. I used the excellent Jackalope fuzzer built and maintained by Ivan Fratric. I chose Jackalope primarily for its high level of customizability—it allows easy implementation of custom mutators, instrumentation, and sample delivery. Additionally, I appreciated its seamless usage on macOS, particularly its code coverage capabilities powered by TinyInst. In contrast, I tried and failed to collect code coverage using Frida against system daemons on macOS.
I used the following command to start a Jackalope fuzzing run:
$ jackalope -in in/ -out out/ -delivery file -instrument_module CoreAudio -target_module harness -target_method _fuzz -nargs 1 -iterations 1000 -persist -loop -dump_coverage -cmp_coverage -generate_unwind -nthreads 5 — ./harness -f @@
Iterate on the Fuzzing Harness
This harness quickly generated many crashes, a sign I was on the right track. However, I quickly learned that initial crashes are often not indicative of a security bug, but of a design bug in the fuzzing harness itself or an invalid assumption.
Iteration 1: Target Initialization
One of the difficulties with my fuzzing approach was that my target function (the Mach message handler) expected the HAL system to be in a specific state to begin receiving Mach messages. By simply calling the library function with my fuzzing harness, these assumptions were broken.
This caused errors to start popping up. As shown in the diagram below, the harness bypassed much of the bootstrapping functionality the coreaudiod process would normally take care of during startup.

Code coverage, as well as error messages, can be very helpful in helping determine some of the initialization steps a fuzzing harness is neglecting. For example, I noticed my data flow would always fail early in most Mach message handlers, logging the message Error: there is no system.

It turns out I needed to initialize the HAL System before I could interact correctly with the Mach APIs. In my case, calling the _AudioHardwareStartServer function in my fuzzing harness took care of most of the necessary initialization.
Iteration 2: API Call Chaining
My first crack at a fuzzing harness was cool, but it made a pretty large assumption: all accessible Mach message handlers functioned independently of each other. As I quickly learned, this assumption was incorrect. As I ran the fuzzer, error messages like the following one started popping up:

The error seemed to indicate the SetPropertyData Mach handler was expecting a client to be registered via a previous Mach message. Clearly, the Mach handlers I was fuzzing were stateful and depended on each other to function properly. My fuzzing harness would need to take this into consideration in order to have any hope of obtaining good code coverage on the target.
This highlights a common problem in the fuzzing world: most coverage-guided fuzzers accept a single input, (a bunch of bytes) while many things we want to fuzz accept data in a completely different format, such as several arguments of different types, or even several function calls. This Google writeup explains the problem well, as does Ned Williamson’s OffensiveCon Talk from 2019.
To get around this limitation, we can use a technique I refer to as API Call Chaining, which considers each fuzz input as a stream that can be read from to craft multiple valid inputs. Thus, each fuzzing iteration would be capable of generating multiple Mach messages. This simple but important insight allows a fuzzer to explore the interdependency of separate function calls using the same code-coverage informed input.
The FuzzedDataProvider class, which is part of LibFuzzer but can be included as a header for use with any fuzzing harness, is a great choice for consuming a fuzz sample and transforming it into a more meaningful data type. Consider the following pseudocode:
extern “C” int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
FuzzedDataProvider fuzz_data(data, size); // Initialize FDP
while (fuzz_data.remaining_bytes() >= MACH_MSG_MIN_SIZE) { // Continue until we’ve consumed all bytes
uint32_t msg_id = fuzz_data.ConsumeIntegralInRange<uint32_t>(1010000, 1010062);
switch (msg_id) {
case ‘1010000’: {
send_XSystem_Open_msg(fuzz_data);
}
case ‘1010001’: {
send_XSystem_Close_msg(fuzz_data);
}
case ‘1010002’: {
send_XSystem_GetObjectInfo_msg(fuzz_data);
}
… continued
}
}
}
This code transforms a blob of bytes into a mechanism that can repeatedly call APIs with fuzz data in a deterministic manner. What’s more, a coverage-guided fuzzer will be able to explore and identify a series of API calls that improves code coverage. From the fuzzer’s perspective, it is simply modifying an array of bytes, blissfully unaware of the additional complexity happening under the hood.
For example, my fuzzer quickly identified that most interactions with the audiohald service required a call to the _XSystem_Open message handler to register a client before most APIs could be called. The inputs the fuzzer saved to its corpus naturally reflected this fact over time.
Iteration 3: Mocking Out Buggy/Unneeded Functionality
Sometimes coverage plateaus, and a fuzzer struggles to explore new code paths. For example, say we’re fuzzing an HTTP server and it keeps getting stuck because it’s trying to read and parse configuration files on startup. If our focus was on the server’s request parsing and response logic, we might choose to mock out the functionality we don’t care about in order to focus the fuzzer’s code coverage exploration elsewhere.
In my fuzzing harness’ case, calling the initialization routines was causing my harness to try to register the com.apple.audio.audiohald Mach service with the bootstrap server, which was throwing an error because it was already registered by launchd. Since my harness didn’t need to register the Mach service in order to inject messages, (remember, our harness calls the MIG subsystem directly) I decided to mock out the functionality.
When dealing with pure C functions, function interposing can be used to easily modify a function’s behavior. In the example below, I declare a new version of the bootstrap_check_in function that just says returns KERN_SUCCESS, effectively nopping it out while telling the caller that it was successful.
#include <mach/mach.h>
#include <stdarg.h>
// Forward declaration for bootstrap_check_in
kern_return_t bootstrap_check_in(mach_port_t bootstrap_port, const char *service_name, mach_port_t *service_port);
// Custom implementation of bootstrap_check_in
kern_return_t custom_bootstrap_check_in(mach_port_t bootstrap_port, const char *service_name, mach_port_t *service_port) {
// Ensure service_port is non-null and set it to a non-zero value
if (service_port) {
*service_port = 1; // Set to a non-zero value
}
return KERN_SUCCESS; // Return 0 (KERN_SUCCESS)
}
// Interposing array for bootstrap_check_in
__attribute__((used)) static struct {
const void* replacement;
const void* replacee;
} interposers[] __attribute__((section(“__DATA,__interpose”))) = {
{ (const void *)custom_bootstrap_check_in, (const void *)bootstrap_check_in }
};
In the case of C++ functions, I used TinyInst’s Hook API to modify problematic functionality. In one specific scenario, my fuzzer was crashing the target constantly because the CFRelease function was being called with a NULL pointer. Some further analysis told me that this was a non-security relevant bug where a user’s input, which was assumed to contain a valid plist object, was not properly validated. If the plist object was invalid or NULL, a downstream function call would contain NULL, and an abort would occur.

So, I wrote the following TinyInst hook, which checked whether the plist object passed into the function was NULL. If so, my hook returned the function call early, bypassing the buggy code.
void HALSWriteSettingHook::OnFunctionEntered() {
printf(“HALS_SettingsManager::_WriteSetting Enteredn”);
if (!GetRegister(RDX)) {
printf(“NULL plist passed as argument, returning to prevent NULL CFReleasen”);
printf(“Current $RSP: %pn”, GetRegister(RSP));
void *return_address;
RemoteRead((void*)GetRegister(RSP), &return_address, sizeof(void *));
printf(“Current return address: %pn”, GetReturnAddress());
printf(“Current $RIP: %pn”, GetRegister(RIP));
SetRegister(RAX, 0);
SetRegister(RIP, GetReturnAddress());
printf(“$RIP register is now: %pn”, GetRegister(ARCH_PC));
SetRegister(RSP, GetRegister(RSP) + 8); // Simulate a ret instruction
printf(“$RSP is now: %pn”, GetRegister(RSP));
}
}
Next, I modified Jackalope to use my instrumentation using the CreateInstrumentation API. That way, my hook was applied during each fuzzing iteration, and the annoying NULL CFRelease calls stopped happening. The output below shows the hook preventing a crash from a NULL plist object passed the troublesome API:
Instrumented module CoreAudio, code size: 7516156
Hooking function __ZN11HALS_System13_WriteSettingEP11HALS_ClientPK10__CFStringPKv in module CoreAudio
HALS_SettingsManager::_WriteSetting Entered
NULL plist passed as argument, returning to prevent NULL CFRelease
Current $RSP: 0x7ff7bf83b358
Current return address: 0x7ff8451e7430
Current $RIP: 0x7ff84533a675
$RIP register is now: 0x7ff8451e7430
$RSP is now: 0x7ff7bf83b360
Total execs: 6230
Unique samples: 184 (0 discarded)
Crashes: 3 (2 unique)
Hangs: 0
Offsets: 13550
Execs/s: 134
The code to reproduce and build this fuzzer with custom instrumentation can be found here: https://github.com/googleprojectzero/p0tools/tree/master/CoreAudioFuzz/jackalope-modifications
Iteration 4: Improving Sample Structure
The great thing about a fuzzing-centric auditing technique is that it highlights knowledge gaps in the code you are auditing. As you address these gaps, you gain a deeper understanding of the structure and constraints of the inputs that your fuzzing harness should generate. These insights enable you to refine your harness to produce more targeted inputs, effectively penetrating deeper code paths and improving overall code coverage. The following subsections highlight examples of how I identified and implemented opportunities to iterate on my fuzzing harness, significantly enhancing its efficiency and effectiveness.
Message Handler Syntax Checks
Code coverage results from fuzzing runs are incredibly telling. I noticed that after running my fuzzer for a few days, it was having trouble exploring past the beginning of most of the Mach message handlers. One simple example is shown below, (explored basic blocks are highlighted in blue) where several comparisons were not being passed , causing the function to error out early on. Here, the rdi register is the incoming Mach message we sent to the handler.

The comparisons were checking that the Mach message was well formatted, with a message length set to 0x34 and various options set within the message. If it wasn’t, it was discarded.
With this in mind, I modified my fuzzing harness to set the fields in the Mach messages I sent to the _XIOContext_SetClientControlPort handler such that they passed these conditions. The fuzzer could modify other pieces of the message as it pleased, but since these aspects needed to conform to strict guidelines, I simply hardcoded them.
These small modifications were the beginning of an input structure I was building for my target. The efficiency of my fuzzing improved astronomically after adding these guidelines to the fuzzer – my code coverage increased by 2000% shortly thereafter.
Out-of-Line (OOL) Message Data
I noticed my fuzzing setup started generating tons of crashes from a call to mig_deallocate, which frees a given address. At first, I thought I had found an interesting bug, since I could control the address passed to mig_deallocate:
I quickly learned, however, that Mach messages can contain various types of Out-of-line (OOL) data. This allows a client to allocate a memory region and place a pointer to it within the Mach message, which will be processed and, in some cases, freed by the message handler. When sending a Mach message with the mach_msg API, the XNU kernel will validate that the memory pointed to by OOL descriptors is properly owned and accessible by the client process.
I hadn’t found a vulnerability; my fuzzing harness was simply attached to the target at a point downstream which bypassed the normal memory checks that would have been performed by the kernel. To remedy this, I modified my fuzzing harness to support allocating space for OOL data and passing the valid memory address within the Mach messages I fuzzed.
The Vulnerability
After many fuzzing harness iterations, lldb “next instruction” commands, and hours spent overheating my MacBook Pro, I had finally begun to acquire an understanding of the CoreAudio framework and generate some meaningful crashes.
But first, some background knowledge.
The Hardware Abstraction Layer (HAL)
The com.apple.audio.audiohald Mach service exposes an interface known as the Hardware Abstraction Layer (HAL). The HAL allows clients to interact with audio devices, plugins, and settings on the operating system, represented in the coreaudiod process as C++ objects of type HALS_Object.
In order to interact with the HAL, a client must first register itself. There are a few ways to do this, but the simplest is using the _XSystem_Open Mach API. Calling this API will invoke the HALS_System::AddClient method, which uses the Mach message’s audit token to create a client (clnt) HALS_Object to map subsequent requests to that client. The code block below shows an IDA decompilation snippet of the creation of a clnt object.
v85[0] = v5 != 0;
v28 = v83[0];
v29 = ‘clnt’;
HALS_Object::HALS_Object((HALS_Object *)v13, ‘clnt’, 0, (__int64)v83[0], v30);
*(_QWORD *)v13 = &unk_7FF850E56640;
*(_OWORD *)(v13 + 72) = 0LL;
*(_OWORD *)(v13 + 88) = 0LL;
*(_DWORD *)(v13 + 104) = 1065353216;
Stepping into the HALS_Object constructor, a mutex is acquired before getting the next available object ID before making a call to HALS_ObjectMap::MapObject.
void __fastcall HALS_Object::HALS_Object(HALS_Object *this, _BOOL4 a2, unsigned int a3, __int64 a4, HALS_Object *a5)
{
unsigned int v5; // r12d
HALB_Mutex::Locker *v6; // r15
unsigned int v7; // ebx
HALS_Object *v8; // rdx
int v9; // eax
v5 = a3;
*(_QWORD *)this = &unk_7FF850E7C200;
*((_DWORD *)this + 2) = 0;
*((_DWORD *)this + 3) = HALB_MachPort::CreatePort(0LL, a2, a3);
*((_WORD *)this + 8) = 257;
*((_WORD *)this + 10) = 1;
pthread_once(&HALS_ObjectMap::sObjectInfoListInitialized, HALS_ObjectMap::Initialize);
v6 = HALS_ObjectMap::sObjectInfoListMutex;
HALB_Mutex::Lock(HALS_ObjectMap::sObjectInfoListMutex);
v7 = (unsigned int)HALS_ObjectMap::sNextObjectID;
LODWORD(HALS_ObjectMap::sNextObjectID) = (_DWORD)HALS_ObjectMap::sNextObjectID + 1;
HALB_Mutex::Locker::~Locker(v6);
*((_DWORD *)this + 6) = v7;
*((_DWORD *)this + 7) = a2;
if ( !v5 )
v5 = a2;
*((_DWORD *)this + 8) = v5;
if ( a4 )
v9 = *(_DWORD *)(a4 + 24);
else
v9 = 0;
*((_DWORD *)this + 9) = v9;
*((_QWORD *)this + 5) = &stru_7FF850E86420;
*((_BYTE *)this + 48) = 0;
*((_DWORD *)this + 13) = 0;
HALS_ObjectMap::MapObject((HALS_ObjectMap *)v7, (__int64)this, v8);
}
The HALS_ObjectMap::MapObject function adds the freshly allocated object to a linked list stored on the heap. I wrote a program using the TinyInst Hook API that iterates through each object in the list and dumps its raw contents:

To modify an existing HALS_Object, most of the HAL Mach message handlers use the HALS_ObjectMap::CopyObjectByObjectID function, which accepts an integer ID (parsed from the Mach message’s body) for a given HALS_Object, which it then looks up in the Object Map and returns a pointer to the object.
For example, here’s a small snippet of the _XSystem_GetObjectInfo Mach message handler, which calls the HALS_ObjectMap::CopyObjectByObjectID function before accessing information about the object and returning it.
HALS_Client::EvaluateSandboxAllowsMicAccess(v5);
v7 = (HALS_ObjectMap *)HALS_ObjectMap::CopyObjectByObjectID((HALS_ObjectMap *)v3);
v8 = v7;
if ( !v7 )
{
v13 = __cxa_allocate_exception(0x10uLL);
*(_QWORD *)v13 = &unk_7FF850E85518;
v13[2] = 560947818;
__cxa_throw(v13, (struct type_info *)&`typeinfo for‘CAException, CAException::~CAException);
}
An Intriguing Crash
Whenever my fuzzer produced a crash, I always took the time to fully understand the crash’s root cause. Often, the crashes were not security relevant, (i.e. a NULL dereference) but fully understanding the reason behind the crash helped me understand the target better and invalid assumptions I was making with my fuzzing harness. Eventually, when I did identify security relevant crashes, I had a good understanding of the context surrounding them.
The first indication from my fuzzer that a vulnerability might exist was a memory access violation during an indirect call instruction, where the target address was calculated using an index into the rax register. As shown in the following backtrace, the crash occurred shallowly within the _XIOContext_Fetch_Workgroup_Port Mach message handler.

Further investigating the context of the crash in IDA, I noticed that the rax register triggering the invalid memory access was directly derived from a call to the HALS_ObjectMap::CopyObjectByObjectID function.

Specifically, it attempted the following:
- Fetch a HALS_Object from the Object Map based on an ID provided in the Mach message
- Dereference the address a1 at offset 0x68 of the HALS_Object
- Dereference the address a2 at offset 0x0 of a1
- Call the function pointer at offset 0x168 of a2
What Went Wrong?
The operations leading to the crash indicated that at offset 0x68 of the HALS_Object it fetched, the code expected a pointer to an object with a vtable. The code would then look up a function within the vtable, which would presumably retrieve the object’s “workgroup port.”
When the fetched object was of type ioct, (IOContext) everything functioned as normal. However, the test input my fuzzer generated was causing the function to fetch a HALS_Object of a different type, which led to an invalid function call. The following diagram shows how an attacker able to influence the pointer at offset 0x68 of a HALS_Object might hijack control flow.

This vulnerability class is referred to as a type confusion, where the vulnerable code makes the assumption that a retrieved object or struct is a specific type, but it is possible to provide a different one. The object’s memory layout might be completely different, meaning memory accesses and vtable lookups might occur in the wrong place, or even out of bounds. Type confusion vulnerabilities can be extremely powerful due to their ability to form reliable exploits.
Affected Functions
The _XIOContext_Fetch_Workgroup_Port Mach message handler wasn’t the only function that assumed it was dealing with an ioct object without checking the type. The table below shows several other message handlers that suffered from the same issue:
Mach Message Handler | Affected Routine |
_XIOContext_Fetch_Workgroup_Port | _XIOContext_Fetch_Workgroup_Port |
_XIOContext_Start | ___ZNK14HALS_IOContext22HasEnabledInputStreamsEv_block_invoke |
_XIOContext_StartAtTime | ___ZNK14HALS_IOContext16GetNumberStreamsEb_block_invoke |
_XIOContext_Start_With_WorkInterval | ___ZNK14HALS_IOContext22HasEnabledInputStreamsEv_block_invoke |
_XIOContext_SetClientControlPort | _XIOContext_SetClientControlPort |
_XIOContext_Stop | _XIOContext_Stop |
Apple did perform proper type checking on some of the Mach message handlers. For example, the _XIOContent_PauseIO message handler, shown below, calls a function that checks whether the fetched object is of type ioct before using it. It is not clear why these checks were implemented in certain areas, but not others.

The impact of this vulnerability can range from an information leak to control flow hijacking. In this case, since the vulnerable code is performing a function call, an attacker could potentially control the data at the offset read during the type confusion, allowing them to control the function pointer and redirect execution. Alternatively, if the attacker can provide an object smaller than 0x68 bytes, an out-of-bounds read would be possible, paving the way for further exploitation opportunities such as memory corruption or arbitrary code execution.
Creating a Proof of Concept
Because my fuzzing harness was connected downstream in the Mach message handling process, it was important to build an end-to-end proof-of-concept that used the mach_msg API to send a Mach message to the vulnerable message handler within coreaudiod. Otherwise, we might have triggered a false positive as we did in the case of the mig_deallocate crash where we thought we had a bug, but were actually just bypassing security checks.
In this case, however, the bug was triggerable using the mach_msg API, making it a legitimate opportunity for use as a sandbox escape. The proof-of-concept code I put together for triggering this issue on MacOS Sequoia 15.0.1 can be found here.
It’s worth noting that code running on Apple Silicon uses Pointer Authentication Codes (PACs) , which could make exploitation more difficult. In order to exploit this bug through an invalid vtable call, an attacker would need the ability to sign pointers, which would be possible if the attacker gained native code execution in an Apple-signed process. However, I only analyzed and tested this issue on x86-64 versions of MacOS.
How Apple Fixed the Issue
I reported this type confusion vulnerability to Apple on October 9, 2024. It was fixed on December 11, 2024, assigned CVE-2024-54529, and a patch was introduced in MacOS Sequoia 15.2, Sonoma 14.7.2, and Ventura 13.7.2. Interestingly, Apple mentions that the vulnerability allowed for code execution with kernel privileges. That part interested me, since as far as I could tell the execution was only possible as the _coreaudiod group, which was not equivalent to kernel privileges.

Apple’s fix was simple: since each HALS Object contains information about its type, the patch adds a check within the affected functions to ensure the fetched object is of type ioct before dereferencing the object and performing a function call.

You might have noticed how the offset derefenced within the HALS Object is 0x70 in the updated version, but was 0x68 in the vulnerable version. Often, such struct modifications are not security relevant, but will differ based on other bug fixes or added features.
Recommendations
To prevent similar type confusion vulnerabilities in the future, Apple should consider modifying the CopyObjectByObjectID function (or any others that make assumptions about an object’s type) to include a type check. This could be achieved by passing the expected object type as an argument and verifying the type of the fetched object before returning it. This approach is similar to how deserialization functions often include a template parameter to ensure type safety.
Conclusion
This blog post described my journey into the world of MacOS vulnerability research and fuzzing. I hope I have shown how a knowledge-driven fuzzing approach can allow rapid prototyping and iteration, a deep understanding of the target, and high impact bugs.
In my next post, I will perform a detailed walkthrough of my experience attempting to exploit CVE-2024-54529.