



Posted by Mateusz Jurczyk, Google Project Zero
In the first three blog posts of this series, I sought to outline what the Windows Registry actually is, its role, history, and where to find further information about it. In the subsequent three posts, my goal was to describe in detail how this mechanism works internally – from the perspective of its clients (e.g., user-mode applications running on Windows), the regf format used to encode hives, and finally the kernel itself, which contains its canonical implementation. I believe all these elements are essential for painting a complete picture of this subsystem, and in a way, it shows my own approach to security research. One could say that going through this tedious process of getting to know the target unnecessarily lengthens the total research time, and to some extent, they would be right. On the other hand, I believe that to conduct complete research, it is equally important to answer the question of how certain things are implemented, as well as why they are implemented that way – and the latter part often requires a deeper dive into the subject. And since I have already spent the time reverse engineering and understanding various internal aspects of the registry, there are great reasons to share the information with the wider community. There is a lack of publicly available materials on how various mechanisms in the registry work, especially the most recent and most complicated ones, so I hope that the knowledge I have documented here will prove useful to others in the future.
In this blog post, we get to the heart of the matter, the actual security of the Windows Registry. I’d like to talk about what made a feature that was initially meant to be just a quick test of my fuzzing infrastructure draw me into manual research for the next 1.5 ~ 2 years, and result in Microsoft fixing (so far) 53 CVEs. I will describe the various areas that are important in the context of low-level security research, from very general ones, such as the characteristics of the codebase that allow security bugs to exist in the first place, to more specific ones, like all possible entry points to attack the registry, the impact of vulnerabilities and the primitives they generate, and some considerations on effective fuzzing and where more bugs might still be lurking.
Let’s start with a quick recap of the registry’s most fundamental properties as an attack surface:
- Local attack surface for privilege escalation: As we already know, the Windows Registry is a strictly local attack surface that can potentially be leveraged by a less privileged process to gain the privileges of a higher privileged process or the kernel. It doesn’t have any remote components except for the Remote Registry service, which is relatively small and not accessible from the Internet on most Windows installations.
- Complex, old codebase in a memory-unsafe language: The Windows Registry is a vast and complex mechanism, entirely written in C, most of it many years ago. This means that both logic and memory safety bugs are likely to occur, and many such issues, once found, would likely remain unfixed for years or even decades.
- Present in the core NT kernel: The registry implementation resides in the core Windows kernel executable (ntoskrnl.exe), which means it is not subject to mitigations like the win32k lockdown. Of course, the reachability of each registry bug needs to be considered separately in the context of specific restrictions (e.g., sandbox), as some of them require file system access or the ability to open a handle to a specific key. Nevertheless, being an integral part of the kernel significantly increases the chances that a given bug can be exploited.
- Most code reachable by unprivileged users: The registry is a feature that was created for use by ordinary user-mode applications. It is therefore not surprising that the vast majority of registry-related code is reachable without any special privileges, and only a small part of the interface requires administrator rights. Privilege escalation from medium IL (Integrity Level) to the kernel is probably the most likely scenario of how a registry vulnerability could be exploited.
- Manages sensitive information: In addition to the registry implementation itself being complex and potentially prone to bugs, it’s important to remember that the registry inherently stores security-critical system information, including various global configurations, passwords, user permissions, and other sensitive data. This means that not only low-level bugs that directly allow code execution are a concern, but also data-only attacks and logic bugs that permit unauthorized modification or even disclosure of registry keys without proper permissions.
- Not trivial to fuzz, and not very well documented: Overall, it seems that the registry is not a very friendly target for bug hunting without any knowledge of its internals. At the same time, obtaining the information is not easy either, especially for the latest registry mechanisms, which are not publicly documented and learning about them basically boils down to reverse engineering. In other words, the entry bar into this area is quite high, which can be an advantage or a disadvantage depending on the time and commitment of a potential researcher.
Security properties
The above cursory analysis seems to indicate that the registry may be a good audit target for someone interested in EoP bugs on Windows. Let’s now take a closer look at some of the specific low-level reasons why the registry has proven to be a fruitful research objective.
Broad range of bug classes
Due to the registry being both complex and a central mechanism in the system operating with kernel-mode privileges, numerous classes of bugs can occur within it. An example vulnerability classification is presented below:
- Hive memory corruption: Every invasive operation performed on the registry (i.e., a “write” operation) is reflected in changes made to the memory-mapped view of the hive’s structure. Considering that objects within the hive include variable-length arrays, structures with counted references, and references to other cells via cell indexes (hives’ equivalent of memory pointers), it’s natural to expect common issues like buffer overflows or use-after-frees.
- Pool memory corruption: In addition to hive memory mappings, the Configuration Manager also stores a significant amount of information on kernel pools. Firstly, there are cached copies of certain hive data, as described in my previous blog post. Secondly, there are various auxiliary objects, such as those allocated and subsequently released within a single system call. Many of these objects can fall victim to memory management bugs typical of the C language.
- Information disclosure: Because the registry implementation is part of the kernel, and it exchanges large amounts of information with unprivileged user-mode applications, it must be careful not to accidentally disclose uninitialized data from the stack or kernel pools to the caller. This can happen both through output data copied to user-mode memory and through other channels, such as data leakage to a file (hive file or related log file). Therefore, it is worthwhile to keep an eye on whether all arrays and dynamically allocated buffers are fully populated or carefully filled with zeros before passing them to a lower-privileged context.
- Race conditions: As a multithreaded environment, Windows allows for concurrent registry access by multiple threads. Consequently, the registry implementation must correctly synchronize access to all shared kernel-side objects and be mindful of “double fetch” bugs, which are characteristic of user-mode client interactions.
- Logic bugs: In addition to being memory-safe and free of low-level bugs, a secure registry implementation must also enforce correct high-level security logic. This means preventing unauthorized users from accessing restricted keys and ensuring that the registry operates consistently with its documentation under all circumstances. This requires a deep understanding of both the explicit documentation and the implicit assumptions that underpin the registry’s security from the kernel developers. Ultimately, any behavior that deviates from expected logic, whether documented or assumed, could lead to vulnerabilities.
- Inter-process attacks: The registry can serve as a security target, but also as a means to exploit flaws in other applications on the system. It is a shared database, and a local attacker has many ways to indirectly interact with more privileged programs and services. A simple example is when privileged code sets overly permissive permissions on its keys, allowing unauthorized reading or modification. More complex cases can occur when there is a race condition between key creation and setting its restricted security descriptor, or when a key modification involving several properties is not performed transactionally, potentially leading to an inconsistent state. The specifics depend on how the privileged process uses the registry interface.
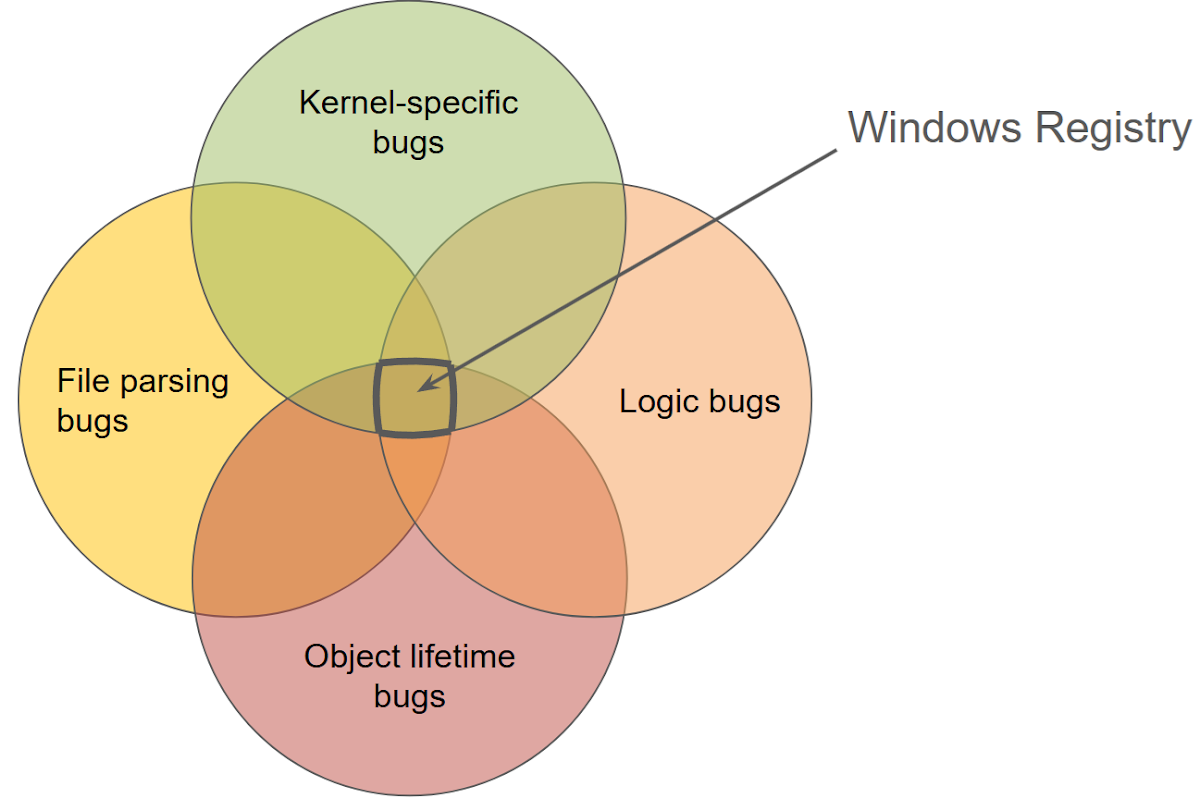
If I were to depict the Windows Registry in a single Venn diagram, highlighting its various possible bug classes, it might look something like this:

Manual reference counting
As I have mentioned multiple times, security descriptors in registry hives are shared by multiple keys, and therefore, must be reference counted. The field responsible for this is a 32-bit unsigned integer, and any situation where it‘s set to a value lower than the actual number of references can result in the release of that security descriptor while it’s still in use, leading to a use-after-free condition and hive-based memory corruption. So, we see that it’s absolutely critical that this refcounting is implemented correctly, but unfortunately, there are (or were until recently) many reasons why this mechanism could be prone to bugs:
- Usually, a reference count is a construct that exists strictly in memory, where it is initialized with a value of 1, then incremented and decremented some number of times, and finally drops to zero, causing the object to be freed. However, with registry hives, the initial refcount values are loaded from disk, from a file that we assume is controlled by the attacker. Therefore, these values cannot be trusted in any way, and the first necessary step is to actually compare and potentially adjust them according to the true number of references to each descriptor. Even though this is done in theory, bugs can creep into this logic in practice (CVE-2022-34707, CVE-2023-38139).
- For a long time, all operations on reference counts were performed by directly referencing the _CM_KEY_SECURITY.ReferenceCount field, instead of using a secure wrapper. As a result, none of these incrementations were protected against integer overflow. This meant that not only a too small, but also a too large refcount value could eventually overflow and lead to a use-after-free situation (CVE-2023-28248, CVE-2024-43641). This weakness was gradually addressed in various places in the registry code between April 2023 and November 2024. Currently, all instances of refcount incrementation appear to be secure and involve calling the special helper function CmpKeySecurityIncrementReferenceCount, which protects against integer overflow. Its counterpart for refcount decrementation is CmpKeySecurityDecrementReferenceCount.
- It seems that there is a lack of clarity and understanding of how certain special types of keys, such as predefined keys and tombstone keys, behave in relation to security descriptors. In theory, the only type of key that does not have a security descriptor assigned to it is the exit node (i.e., a key with the KEY_HIVE_EXIT flag set, found solely in the virtual hive rooted at Registry), while all other keys do have a security descriptor assigned to them, even if it is not used for anything. In practice, however, there have been several vulnerabilities in Windows that resulted either from incorrect security refresh in KCB for special types of keys (CVE-2023-21774), from releasing the security descriptor of a predefined key without considering its reference count (CVE-2023-35356), or from completely forgetting the need for reference counting the descriptors of tombstone keys in the “rename” operation (CVE-2023-35382).
- When the reference count of a security descriptor reaches zero and is released, this operation is irreversible. There is no guarantee that upon reallocation, the descriptor would have the same cell index, or even that it could be reallocated at all. This is crucial for multi-step operations where individual actions could fail, necessitating a full rollback to the original state. Ideally, releasing security descriptors should always be the final step, only when the kernel can be certain that the entire operation will succeed. A vulnerability exemplifying this is CVE-2023-21772, where the registry virtualization code first released the old security descriptor and then attempted to allocate a new one. If the allocation failed, the key was left without any security properties, violating a fundamental assumption of the registry and potentially having severe consequences for system memory safety.
Aggressive self-healing and recovery
As I described in blog post #5, one of the registry’s most interesting features, which distinguishes it from many other file format implementations, is that it is self-healing. The entire hive loading process, from the internal CmCheckRegistry function downwards, is focused on loading the database at all costs, even if some corrupted fragments are encountered. Only if the file damage is so extensive that recovering any data is impossible does the entire loading process fail. Of course, given that the registry stores critical system data such as its basic configuration, and the lack of access to this data virtually prevents Windows from booting, this decision made a lot of sense from the system reliability point of view. It’s probably safe to assume that it has prevented the need for system reinstallation on numerous computers, simply because it did not reject hives with minor damage that might have appeared due to random hardware failure.
However, from a security perspective, this behavior is not necessarily advantageous. Firstly, it seems obvious that upon encountering an error in the input data, it is simpler to unconditionally halt its processing rather than attempt to repair it. In the latter case, it is possible for the programmer to overlook an edge case – forget to reset some field in some structure, etc. – and thus instead of fixing the file, allow for another unforeseen, inconsistent state to materialize within it. In other words, the repair logic constitutes an additional attack surface, and one that is potentially even more interesting and error-prone than other parts of the implementation. A classic example of a vulnerability associated with this property is CVE-2023-38139.
Secondly, in my view, the existence of this logic may have negatively impacted the secure development of the registry code, perhaps by leading to a discrepancy between what it guaranteed and what other developers thought it had guaranteed. For example, in 1991–1993, when the foundations of the Configuration Manager subsystem were being created in their current form, probably no one considered hive loading a potential attack vector. At that time, the registry was used only to store system configuration, and controlled hive loading was privileged and required admin rights. Therefore, I suspect that the main goal of hive checking at that time was to detect simple data inconsistencies due to hardware problems, such as single bit flips. No one expected a hive to contain a complex, specially crafted multi-kilobyte data structure designed to trigger a security flaw. Perhaps the rest of the registry code was written under the assumption that since data sanitization and self-healing occurred at load time, its state was safe from that point on and no further error handling was needed (except for out-of-memory errors). Then, in Windows Vista, a decision was made to open access to controlled hive loading by unprivileged users through the app hive mechanism, and it suddenly turned out that the existing safeguards were not entirely adequate. Attackers now became able to devise data constructs that were structurally correct at the low level, but completely beyond the scope of what the actual implementation expected and could handle.
Finally, self-healing can adversely affect system security by concealing potential registry bugs that could trigger during normal Windows operation. These problems might only become apparent after a period of time and with a “build-up” of enough issues within the hive. Because hives are mapped into memory, and the kernel operates directly on the data within the file, there exists a category of errors known as “inconsistent hive state”. This refers to a data structure within the hive that doesn’t fully conform to the file format specification. The occurrence of such an inconsistency is noteworthy in itself and, for someone knowledgeable about the registry, it could be a direct clue for finding vulnerabilities. However, such instances rarely cause an immediate system crash or other visible side effects. Consider security descriptors and their reference counting: as mentioned earlier, any situation where the active number of references exceeds the reference count indicates a serious security flaw. However, even if this were to happen during normal system operation, it would require all other references to that descriptor to be released and then for some other data to overwrite the freed descriptor. Then, a dangling reference would need to be used to access the descriptor. The occurrence of all these factors in sequence is quite unlikely, and the presence of self-healing further decreases these chances, as the reference count would be restored to its correct value at the next hive load. This characteristic can be likened to wrapping the entire registry code in a try/except block that catches all exceptions and masks them from the user. This is certainly helpful in the context of system reliability, but for security, it means that potential bugs are harder to spot during system run time and, for the same reason, quite difficult to fuzz. This does not mean that they don’t exist; their detection just becomes more challenging.
Unclear boundaries between hard and conventional format requirements
This point is related to the previous section. In the regf format, there are certain requirements that are fairly obvious and must be always met for a file to be considered valid. Likewise, there are many elements that are permitted to be formatted arbitrarily, at the discretion of the format user. However, there is a third category, a gray area of requirements that seem reasonable and probably would be good if they were met, but it is not entirely clear whether they are formally required. Another way to describe this set of states is one that is not generated by the Windows kernel itself but is still not obviously incorrect. From a researcher’s perspective, it would be worthwhile to know which parts of the format are actually required by the specification and which are only a convention adopted by the Windows code.
We might never find out, as Microsoft hasn’t published an official format specification and it seems unlikely that they will in the future. The only option left for us is to rely on the implementation of the CmpCheck* functions (CmpCheckKey, CmpCheckValueList, etc.) as a sort of oracle and assume that everything there is enforced as a hard requirement, while all other states are permissible. If we go down this path, we might be in for a big surprise, as it turns out that there are many logical-sounding requirements that are not enforced in practice. This could allow user-controlled hives to contain constructs that are not obviously problematic, but are inconsistent with the spirit of the registry and its rules. In many cases, they allow encoding data in a less-than-optimal way, leading to unexpected redundancy. Some examples of such constructs are presented below:
- Values with duplicate names within a single key: Under normal conditions, only one value with a given name can exist in a key, and if there is a subsequent write to the same name, the new data is assigned to the existing value. However, the uniqueness of value names is not required in input hives, and it is possible to load a hive with duplicate values.
- Duplicate identical security descriptors within a single hive: Similar to the previous point, it is assumed that security descriptors within a hive are unique, and if an existing descriptor is assigned to another key, its reference count is incremented rather than allocating a new object. However, there is no guarantee that a specially crafted hive will not contain multiple duplicates of the same security descriptor, and this is accepted by the loader.
- Uncompressed key names consisting solely of ASCII characters: Under normal circumstances, if a given key has a name comprising only ASCII characters, it will always be stored in a compressed form, i.e., by writing two bytes of the name in each element of the _CM_KEY_NODE.Name array of type uint16, and setting the KEY_COMP_NAME flag (0x20) in _CM_KEY_NODE.Flags. However, once again, optimal representation of names is not required when loading the hive, and this convention can be ignored without issue.
- Allocated but unused cells: The Windows registry implementation deallocates objects within a hive when they are no longer needed, making space for new data. However, the loader does not require every cell marked “allocated” to be actively used. Similarly, security descriptors with a reference count of zero are typically deallocated. However, until a November 2024 refactor of the CmpCheckAndFixSecurityCellsRefcount function, it was possible to load a hive with unused security descriptors still present in the linked list. This behavior has since been changed, and unused security descriptors encountered during loading are now automatically freed and removed from the list.
These examples illustrate the issue well, but none of them (as far as I know) have particularly significant security implications. However, there were also a few specific memory corruption vulnerabilities that stemmed from the fact that the registry code made theoretically sound assumptions about the hive structure, but they were not unenforced by the loader:
- CVE-2022-37988: This bug is closely related to the fact that cells larger than 16 KiB are aligned to the nearest power of two in Windows, but this condition doesn’t need to be satisfied during loading. This caused the shrinking of a cell to fail, even though it should always succeed in-place, “surprising” the client of the allocator and resulting in a use-after-free condition.
- CVE-2022-37956: As I described in blog post #5, Windows has some logic to ensure that no leaf-type subkey list (li, lf, or lh) exceeds 511 or 1012 elements, depending on its specific type. If a list is expanded beyond this limit, it is automatically split into two lists, each half the original length. Another reasonable assumption is that the root index length would never approach the maximum value of _CM_KEY_INDEX.Count (uint16) under normal circumstances. This would require an unrealistically large number of subkeys or a very specific sequence of millions of key creations and deletions with specific names. However, it was possible to load a hive containing a subkey list of any of the four types with a length equal to 0xFFFF, and trigger a 16-bit integer overflow on the length field, leading to memory corruption. Interestingly, this is one of the few bugs that could be triggered solely with a single .bat file containing a long sequence of the reg.exe command executions.
- CVE-2022-38037: In this case, the kernel code assumed that the hive version defined in the header (_HBASE_BLOCK.Minor) always corresponded to the type of subkey lists used in a given hive. For example, if the file version is regf 1.3, it should be impossible for it to contain lists in a format introduced in version 1.5. However, for some reason, the hive loader doesn’t enforce the proper relationship between the format version and the structures used in it, which in this case led to a serious hive-based memory corruption vulnerability.
As we can see, it is crucial to differentiate between format elements that are conventions adopted by a specific implementation, and those actually enforced during the processing of the input file. If we encounter some code that makes assumptions from the former group that don’t belong to the latter one, this could indicate a serious security issue.
Susceptibility to mishandling OOM conditions
Generally speaking, the implementation of any function in the Windows kernel is built roughly according to the following scheme:
NTSTATUS NtHighLevelOperation(…) {
NTSTATUS Status;
Status = HelperFunction1(…);
if (!NT_SUCCESS(Status)) {
//
// Clean up…
//
return Status;
}
Status = HelperFunction2(…);
if (!NT_SUCCESS(Status)) {
//
// Clean up…
//
return Status;
}
//
// More calls…
//
return STATUS_SUCCESS;
}
Of course, this is a significant simplification, as real-world code contains keywords and constructs such as if statements, switch statements, various loops, and so on. The key point is that a considerable portion of higher-level functions call internal, lower-level functions specialized for specific tasks. Handling potential errors signalled by these functions is an important aspect of kernel code (or any code, for that matter). In low-level Windows code, error propagation occurs using the NTSTATUS type, which is essentially a signed 32-bit integer. A value of 0 signifies success (STATUS_SUCCESS), positive values indicate success but with additional information, and negative values denote errors. The sign of the number is checked by the NT_SUCCESS macro. During my research, I dedicated significant time to analyzing the error handling logic. Let’s take a moment to think about the types of errors that could occur during registry operations, and the conditions that might cause them.
A common trait of all actions that modify data in the registry is that they allocate memory. The simplest example is the allocation of auxiliary buffers from kernel pools, requested through functions from the ExAllocatePool group. If there is very little available memory at a given point in time, one of the allocation requests may return the STATUS_INSUFFICIENT_RESOURCES error code, which will be propagated back to the original caller. And since we assume that we take on the role of a local attacker who has the ability to execute code on the machine, artificially occupying all available memory is potentially possible in many ways. So this is one way to trigger errors while performing operations on the registry, but admittedly not an ideal way, as it largely depends on the amount of RAM and the maximum pagefile size. Additionally, in a situation where the kernel has so little memory that single allocations start to fail, there is a high probability of the system crashing elsewhere before the vulnerability is successfully exploited. And finally, if several allocations are requested in nearby code in a short period of time, it seems practically impossible to take precise control over which of them will succeed and which will not.
Nonetheless, the overall concept of out-of-memory conditions is a very promising avenue for attack, especially considering that the registry primarily operates on memory-mapped hives using its own allocator, in addition to objects from kernel pools. The situation is even more favorable for an attacker due to the 2 GiB size limitation of each of the two storage types (stable and volatile) within a hive. While this is a relatively large value, it is achievable to occupy it in under a minute on today’s machines. The situation is even easier if the volatile space that needs to be occupied, as it resides solely in memory and is not flushed to disk – so filling two gigabytes of memory is then a matter of seconds. It can be accomplished, for example, by creating many long registry values, which is a straightforward task when dealing with a controlled hive. However, even in system hives, this is often feasible. To perform data spraying on a given hive, we only need a single key granting us write permissions. For instance, both HKLMSoftware and HKLMSystem contain numerous keys that allow write access to any user in the system, effectively permitting them to fill it to capacity. Additionally, the “global registry quota” mechanism, implemented by the internal CmpClaimGlobalQuota and CmpReleaseGlobalQuota functions, ensures that the total memory occupied by registry data in the system does not exceed 4 GiB. Besides filling the entire space of a specific hive, this is thus another way to trigger out-of-memory conditions in the registry, especially when targeting a hive without write permissions. A concrete example where this mechanism could have been employed to corrupt the HKLMSAM system hive is the CVE-2024-26181 vulnerability.
Considering all this, it is a fair assumption that a local attacker can cause any call to ExAllocatePool*, HvAllocateCell, and HvReallocateCell (with a length greater than the existing cell) to fail. This opens up a large number of potential error paths to analyze. The HvAllocateCell calls are a particularly interesting starting point for analysis, as there are quite a few of them and almost all of them belong to the attack surface accessible to a regular user:

There are two primary reasons why focusing on the analysis of error paths can be a good way to find security bugs. First, it stands to reason that on regular computers used by users, it is extremely rare for a given hive to grow to 2 GiB and run out of space, or for all registry data to simultaneously occupy 4 GiB of memory. This means that these code paths are practically never executed under normal conditions, and even if there were bugs in them, there is a very small chance that they would ever be noticed by anyone. Such rarely executed code paths are always a real treat for security researchers.
The second reason is that proper error handling in code is inherently difficult. Many operations involve numerous steps that modify the hive’s internal state. If an issue arises during these operations, the registry code must revert all changes and restore the registry to its original state (at least from the macro-architectural perspective). This requires the developer to be fully aware of all changes applied so far when implementing each error path. Additionally, proper error handling must be considered during the initial design of the control flow as well, because some registry actions are irreversible (e.g., freeing cells). The code must thus be structured so that all such operations are placed at the very end of the logic, where errors cannot occur anymore and successful execution is guaranteed.
One example of such a vulnerability is CVE-2023-23421, which boiled down to the following code:
NTSTATUS CmpCommitRenameKeyUoW(_CM_KCB_UOW *uow) {
// …
if (!CmpAddSubKeyEx(Hive, ParentKey, NewNameKey) ||
!CmpRemoveSubKey(Hive, ParentKey, OldNameKey)) {
CmpFreeKeyByCell(Hive, NewNameKey);
return STATUS_INSUFFICIENT_RESOURCES;
}
// …
}
The issue here was that if the CmpRemoveSubKey call failed, the corresponding error path should have reversed the effect of the CmpAddSubKeyEx function in the previous line, but in practice it didn’t. As a result, it was possible to end up with a dangling reference to a freed key in the subkey list, which was a typical use-after-free condition.
A second interesting example of this type of bug was CVE-2023-21747, where an out-of-memory error could occur during a highly sensitive operation, hive unloading. As there was no way to revert the state at the time of the OOM, the vulnerability was fixed by Microsoft by refactoring the CmpRemoveSubKeyFromList function and other related functions so that they no longer allocate memory from kernel pools and thus there is no longer a physical possibility of them failing.
Finally, I’ll mention CVE-2023-38154, where the problem wasn’t incorrect error handling, but a complete lack of it – the return value of the HvpPerformLogFileRecovery function was ignored, even though there was a real possibility it could end with an error. This is a fairly classic type of bug that can occur in any programming language, but it’s definitely worth keeping in mind when auditing the Windows kernel.
Susceptibility to mishandling partial successes
The previous section discusses bugs in error handling where each function is responsible for reversing the state it has modified. However, some functions don’t adhere to this operational model. Instead of operating on an “all-or-nothing” basis, they work on a best-effort basis, aiming to accomplish as much of a given task as possible. If an error occurs, they leave any changes made in place, e.g., because this result is still preferable to not making any changes. This introduces a third possible output state for such functions: complete success, partial success, and complete failure.
This might be problematic, as the approach is incompatible with the typical usage of the NTSTATUS type, which is best suited for conveying one of two (not three) states. In theory, it is a 32-bit integer type, so it could store the additional information of the status being a partial success, and not being unambiguously positive or negative. In practice, however, the convention is to directly propagate the last error encountered within the inner function, and the outer functions very rarely “dig into“ specific error codes, instead assuming that if NT_SUCCESS returns FALSE, the entire operation has failed. Such confusion at the cross-function level may have security implications if the outer function should take some additional steps in the event of a partial success of the inner function, but due to the binary interpretation of the returned error code, it ultimately does not execute them.
A classic example of such a bug is CVE-2024-26182, which occurred at the intersection of the CmpAddSubKeyEx (outer) and CmpAddSubKeyToList (inner) functions. The problem here was that CmpAddSubKeyToList implements complex, potentially multi-step logic for expanding the subkey list, which could perform a cell reallocation and subsequently encounter an OOM error. On the other hand, the CmpAddSubKeyEx function assumed that the cell index in the subkey list should only be updated in the hive structures if CmpAddSubKeyToList fully succeeds. As a result, the partial success of CmpAddSubKeyToList could lead to a classic use-after-free situation. An attentive reader will probably notice that the return value type of the CmpAddSubKeyToList routine was BOOL and not NTSTATUS, but the bug pattern is identical.
Overall complexity introduced over time
One of the biggest problems with the modern implementation of the registry is that over the decades of developing this functionality, many changes and new features have been introduced. This has caused the level of complexity of its internal state to increase so much that it seems difficult to grasp for one person, unless they are a full-time registry expert that has worked on it full-time over a period of months or years. I personally believe that the registry existed in its most elegant form somewhere around Windows NT 3.1 – 3.51 (i.e. in the years 1993–1996). At the time, the mechanism was intuitive and logical for both developers and its users. Each object (key, value) either existed or not, each operation ended in either success or failure, and when it was requested on a particular key, you could be sure that it was actually performed on that key. Everything was simple, and black and white. However, over time, more and more shades of gray were being continuously added, departing from the basic assumptions:
- The existence of predefined keys meant that every operation could no longer be performed on every key, as this special type of key was unsafe for many internal registry functions to use due to its altered semantics.
- Due to symbolic links, opening a specific key doesn’t guarantee that it will be the intended one, as it might be a different key that the original one points to.
- Registry virtualization has introduced further uncertainty into key operations. When an operation is performed on a key, it is unclear whether the operation is actually executed on that specific key or redirected to a different one. Similarly, with read operations, a client cannot be entirely certain that it is reading from the intended key, as the data may be sourced from a different, virtualized location.
- Transactions in the registry mean that a given state is no longer considered solely within the global view of the registry. At any given moment, there may also be changes that are visible only within a certain transaction (when they are initiated but not yet committed), and this complex scenario must be correctly handled by the kernel.
- Layered keys have transformed the nature of hives, making them interdependent rather than self-contained database units. This is due to the introduction of differencing hives, which function solely as “patch diffs” and cannot exist independently without a base hive. Additionally, the semantics of certain objects and their fields have been altered. Previously, a key’s existence was directly tied to the presence of a corresponding key node within the hive. Layered keys have disrupted this dependency. Now, a key with a key node can be non-existent if marked as a Tombstone, and a key without a corresponding key node can logically exist if its semantics are Merge-Unbacked, referencing a lower-level key with the same name.
Of course, all of these mechanisms were designed and implemented for a specific purpose: either to make life easier for developers/applications using the Registry API, or to introduce some new functionality that is needed today. The problem is not that they were added, but that it seems that the initial design of the registry was simply not compatible with them, so they were sort of forced into the registry, and where they didn’t fit, an extra layer of tape was added to hold it all together. This ultimately led to a massive expansion of the internal state that needs to be maintained within the registry. This is evident both in the significant increase in the size of old structures (like KCB) and in the number of new objects that have been added over the years. But the most unfortunate aspect is that each of these more advanced mechanisms seems to have been designed to solve one specific problem, assuming that they would operate in isolation. And indeed, they probably do under typical conditions, but a particularly malicious user could start combining these different mechanisms and making them interact. Given the difficulty in logically determining the expected behavior of some of these combinations, it is doubtful that every such case was considered, documented, implemented, and tested by Microsoft.
The relationships between the various advanced mechanisms in the registry are humorously depicted in the image below:

Some examples of bugs caused by incorrect interactions between these mechanisms include CVE-2023-21675, CVE-2023-21748, CVE-2023-35356, CVE-2023-35357 and CVE-2023-35358.
Entry points
This section describes the entry points that a local attacker can use to interact with the registry and exploit any potential vulnerabilities.
Hive loading
Let’s start with the operation of loading user-controlled hives. Since hive loading is only possible from disk (and not, for example, from a memory buffer), this means that to actually trigger this attack surface, the process must be able to create a file with controlled content, or at least a controlled prefix of several kilobytes in length. Regular programs operating at Medium IL generally have this capability, but write access to disk may be restricted for heavily sandboxed processes (e.g. renderer processes in browsers).
When it comes to the typical type of bugs that can be triggered in this way, what primarily comes to mind are issues related to binary data parsing, and memory safety violations such as out-of-bounds buffer accesses. It is possible to encounter more logical-type issues, but they usually rely on certain assumptions about the format not being sufficiently verified, causing subsequent operations on such a hive to run into problems. It is very rare to find a vulnerability that can be both triggered and exploited by just loading the hive, without performing any follow-up actions on it. But as CVE-2024-43452 demonstrates, it can still happen sometimes.
App hives
The introduction of Application Hives in Windows Vista caused a significant shift in the registry attack surface. It allowed unprivileged processes to directly interact with kernel code that was previously only accessible to system services and administrators. Attackers gained access to much of the NtLoadKey syscall logic, including hive file operations, hive parsing at the binary level, hive validation logic in the CmpCheckRegistry function and its subfunctions, and so on. In fact, of the 53 serious vulnerabilities I discovered during my research, 16 (around 30%) either required loading a controlled hive as an app hive, or were significantly easier to trigger using this mechanism.
It’s important to remember that while app hives do open up a broad range of new possibilities for attackers, they don’t offer exactly the same capabilities as loading normal (non-app) hives due to several limitations and specific behaviors:
- They must be loaded under the special path RegistryA, which means an app hive cannot be loaded just anywhere in the registry hierarchy. This special path is further protected from references by a fully qualified path, which also reduces their usefulness in some offensive applications.
- The logic for unloading app hives differs from unloading standard hives because the process occurs automatically when all handles to the hive are closed, rather than manually unloading the hive through the RegUnLoadKeyW API or its corresponding syscall from the NtUnloadKey family.
- Operations on app hive security descriptors are very limited: any calls to the RegSetKeySecurity function or RegCreateKeyExW with a non-default security descriptor will fail, which means that new descriptors cannot be added to such hives.
- KTM transactions are unconditionally blocked for app hives.
Despite these minor restrictions, the ability to load arbitrary hives remains one of the most useful tools when exploiting registry bugs. Even if binary control of the hive is not strictly required, it can still be valuable. This is because it allows the attacker to clearly define the initial state of the hive where the attack takes place. By taking advantage of the cell allocator’s determinism, it is often possible to achieve 100% exploitation success.
User hives and Mandatory User Profiles
Sometimes, triggering a specific bug requires both binary control over the hive and certain features that app hives lack, such as the ability to open a key via its full path. In such cases, an alternative to app hives exists, which might be slightly less practical but still allows for exploiting these more demanding bugs. It involves directly modifying one of the two hives assigned to every user in the system: the user hive (C:UsersNTUSER.DAT mounted under RegistryUser<SID>, or in other words, HKCU) or the user classes hive (C:UsersAppDataLocalMicrosoftWindowsUsrClass.dat mounted under RegistryUser<SID>_Classes). Naturally, when these hives are actively used by the system, access to their backing files is blocked, preventing simultaneous modification, which complicates things considerably. However, there are two ways to circumvent this problem.
The first scenario involves a hypothetical attacker who has two local accounts on the targeted system, or similarly, two different users collaborating to take control of the computer (let’s call them users A and B). User A can grant user B full rights to modify their hive(s), and then log out. User B then makes all the required binary changes to the hive and finally notifies user A that they can log back in. At this point, the Profile Service loads the modified hive on behalf of that user, and the initial goal is achieved.
The second option is more practical as it doesn’t require two different users. It abuses Mandatory User Profiles, a system functionality that prioritizes the NTUSER.MAN file in the user’s directory over the NTUSER.DAT file as the user hive, if it exists (it doesn’t exist in the default system installation). This means that a single user can place a specially prepared hive under the NTUSER.MAN name in their home directory, then log out and log back in. Afterwards, NTUSER.MAN will be the user’s active HKCU key, achieving the goal. However, the technique also has some drawbacks – it only applies to the user hive (not UsrClass.dat), and it is somewhat noisy. Once the NTUSER.MAN file has been created and loaded, there is no way to delete it by the same user, as it will always be loaded by the system upon login, effectively blocking access to it.
A few examples of bugs involving one of the two above techniques are CVE-2023-21675, CVE-2023-35356, and CVE-2023-35633. They all required the existence of a special type of key called a predefined key within a publicly accessible hive, such as HKCU. Even when predefined keys were still supported, they could not be created using the system API, and the only way to craft them was by directly setting a specific flag within the internal key node structure in the hive file.
Log file parsing: .LOG/.LOG1/.LOG2
One of the fundamental features of the registry is that it guarantees consistency at the level of interdependent cells that together form the structure of keys within a given hive. This refers to a situation where a single operation on the registry involves the simultaneous modification of multiple cells. Even if there is a power outage and the system restarts in the middle of performing this operation, the registry guarantees that all intermediate changes will either be applied or discarded. Such “atomicity” of operations is necessary in order to guarantee the internal consistency of the hive structure, which, as we know, is important to security. The mechanism is implemented by using additional files associated with the hive, where the intermediate state of registry modifications is saved with the granularity of a memory page (4 KiB), and which can be safely rolled forward or rolled back at the next hive load. Usually these are two files with the .LOG1 and .LOG2 extensions, but it is also possible to force the use of a single log file with the .LOG extension by passing the REG_HIVE_SINGLE_LOG flag to syscalls from the NtLoadKey family.
Internally, each LOG file can be encoded in one of two formats. One is the “legacy log file”, a relatively simple format that has existed since the first implementation of the registry in Windows NT 3.1. Another one is the “incremental log file”, a slightly more modern and complex format introduced in Windows 8.1 to address performance issues that plagued the previous version. Both formats use the same header as the normal regf format (the first 512 bytes of the _HBASE_BLOCK structure, up to the CheckSum field), with the Type field set to 0x1 (legacy log file on Windows XP and newer), 0x2 (legacy log file on Windows 2000 and older), or 0x6 (incremental log file). Further at offset 0x200, legacy log files contain the signature 0x54524944 (“DIRT”) followed by the “dirty vector”, while incremental log files contain successive records represented by the magic value 0x454C7648 (“HvLE”).
These formats are well-documented in two unofficial regf documentations: GitHub: libyal/libregf and GitHub: msuhanov/regf. Additional information can be found in the “Stable storage” and “Incremental logging” subsections of the Windows Internals (Part 2, 7th Edition) book and its earlier editions.
From a security perspective, it’s important to note that LOG files are processed for app hives, so their handling is part of the local attack surface. On the other hand, this attack surface isn’t particularly large, as it boils down to just a few functions that are called by the two highest-level routines: HvAnalyzeLogFiles and HvpPerformLogFileRecovery. The potential types of bugs are also fairly limited, mainly consisting of shallow memory safety violations. Two specific examples of vulnerabilities related to this functionality are CVE-2023-35386 and CVE-2023-38154.
Log file parsing: KTM logs
Besides ensuring atomicity at the level of individual operations, the Windows Registry also provides two ways to achieve atomicity for entire groups of operations, such as creating a key and setting several of its values as part of a single logical unit. These mechanisms are based on two different types of transactions: KTM transactions (managed by the Kernel Transaction Manager, implemented by the tm.sys driver) and lightweight transactions, which were designed specifically for the registry. Notably, lightweight transactions exist in memory only and are never written to disk, so they do not represent an attack vector during hive loading, because there is no file recovery logic.
KTM transactions are available for use in any loaded hive that doesn’t have the REG_APP_HIVE and REG_HIVE_NO_RM flags. To utilize them, a transaction object must first be created using the CreateTransaction API. The resulting handle is then passed to the RegOpenKeyTransacted, RegCreateKeyTransacted, or RegDeleteKeyTransacted registry functions. Finally, the entire transaction is committed via CommitTransaction. Windows attempts to guarantee that active transactions that are caught mid-commit during a sudden system shutdown will be rolled forward when the hive is loaded again. To achieve this, the Windows kernel employs the Common Log File System interface to save serialized records detailing individual operations to the .blf files that accompany the main hive file. When a hive is loaded, the system checks for unapplied changes in these .blf files. If any are found, it deserializes the individual records and attempts to redo all the actions described within them. This logic is primarily handled by the internal functions CmpRmAnalysisPhase, CmpRmReDoPhase, and CmpRmUnDoPhase, as well as the functions surrounding them in the control flow graph.
Given that KTM transactions are never enabled for app hives, the possibility of an unprivileged user exploiting this functionality is severely limited. The only option is to focus on KTM log files associated with regular hives that a local user has some control over, namely the user hive (NTUSER.DAT) and the user classes hive (UsrClass.dat). If a transactional operation is performed on a user’s HKCU hive, additional .regtrans-ms and .blf files appear in their home directory. Furthermore, if these files don’t exist at first, they can be planted on the disk manually, and will be processed by the Windows kernel after logging out and logging back in. Interestingly, even when the KTM log files are actively in use, they have the read sharing mode enabled. This means that a user can write data to these logs by performing transactional operations, and read from them directly at the same time.
Historically, the handling of KTM logs has been affected by a significant number of security issues. Between 2019 and 2020, James Forshaw reported three serious bugs in this code: CVE-2019-0959, CVE-2020-1377, and CVE-2020-1378. Subsequently, during my research, I discovered three more: CVE-2023-28271, CVE-2023-28272, and CVE-2023-28293. However, the strangest thing is that, according to my tests, the entire logic for restoring the registry state from KTM logs stopped working due to code refactoring introduced in Windows 10 1607 (almost 9 years ago) and has not been fixed since. I described this observation in another report related to transactions, in a section called “KTM transaction recovery code”. I’m not entirely sure whether I’m making a mistake in testing, but if this is truly the case, it means that the entire recovery mechanism currently serves no purpose and only needlessly increases the system’s attack surface. Therefore, it could be safely removed or, at the very least, actually fixed.
Direct registry operations through standard syscalls
Direct operations on keys and values are the core of the registry and make up most of its associated code within the Windows kernel. These basic operations don’t need any special permissions and are accessible by all users, so they constitute the primary attack surface available to a local attacker. These actions have been summarized at the beginning of blog post #2, and should probably be familiar by now. As a recap, here is a table of the available operations, including the corresponding high-level API function, system call name, and internal kernel function name if it differs from the syscall:
|
Operation name |
Registry API name(s) |
System call(s) |
Internal kernel handler (if different than syscall) |
|
Load hive |
NtLoadKey NtLoadKeyEx NtLoadKey3 |
– |
|
|
Count open subkeys in hive |
– |
NtQueryOpenSubKeys |
– |
|
Flush hive |
NtFlushKey |
– |
|
|
Open key |
NtOpenKey NtOpenKeyEx NtOpenKeyTransacted NtOpenKeyTransactedEx |
CmpParseKey |
|
|
Create key |
NtCreateKey NtCreateKeyTransacted |
CmpParseKey |
|
|
Delete key |
NtDeleteKey |
– |
|
|
Rename key |
NtRenameKey |
– |
|
|
Set key security |
NtSetSecurityObject |
CmpSecurityMethod |
|
|
Query key security |
NtQuerySecurityObject |
CmpSecurityMethod |
|
|
Set key information |
– |
NtSetInformationKey |
– |
|
Query key information |
NtQueryKey |
– |
|
|
Enumerate subkeys |
NtEnumerateKey |
– |
|
|
Notify on key change |
NtNotifyChangeKey NtNotifyChangeMultipleKeys |
– |
|
|
Query key path |
– |
NtQueryObject |
CmpQueryKeyName |
|
Close key handle |
NtClose |
CmpCloseKeyObject CmpDeleteKeyObject |
|
|
Set value |
NtSetValueKey |
– |
|
|
Delete value |
NtDeleteValueKey |
– |
|
|
Enumerate values |
NtEnumerateValueKey |
– |
|
|
Query value data |
NtQueryValueKey |
– |
|
|
Query multiple values |
NtQueryMultipleValueKey |
– |
Some additional comments:
- A regular user can directly load only application hives, using the RegLoadAppKey function or its corresponding syscalls with the REG_APP_HIVE flag. Loading standard hives, using the RegLoadKey function, is reserved for administrators only. However, this operation is still indirectly accessible to other users through the NTUSER.MAN hive and the Profile Service, which can load it as a user hive during system login.
- When selecting API functions for the table above, I prioritized their latest versions (often with the “Ex” suffix, meaning “extended”). I also chose those that are the thinnest wrappers and closest in functionality to their corresponding syscalls on the kernel side. In the official Microsoft documentation, you’ll also find many older/deprecated versions of these functions, which were available in early Windows versions and now exist solely for backward compatibility (e.g., RegOpenKey, RegEnumKey). Additionally, there are also helper functions that implement more complex logic on the user-mode side (e.g., RegDeleteTree, which recursively deletes an entire subtree of a given key), but they don’t add anything in terms of the kernel attack surface.
- There are several operations natively supported by the kernel that do not have a user-mode equivalent, such as NtQueryOpenSubKeys or NtSetInformationKey. The only way to use these interfaces is to call their respective system calls directly, which is most easily achieved by calling their wrappers with the same name in the ntdll.dll library. Furthermore, even when a documented API function exists, it may not expose all the capabilities of its corresponding system call. For example, the RegQueryKeyInfo function returns some information about a key, but much more can be learned by using NtQueryKey directly with one of the supported information classes.
Moreover, there is a group of syscalls that do require administrator rights (specifically SeBackupPrivilege, SeRestorePrivilege, or PreviousMode set to KernelMode). These syscalls are used either for registry management by the kernel or system services, or for purely administrative tasks (such as performing registry backups). They are not particularly interesting from a security research perspective, as they cannot be used to elevate privileges, but it is worth mentioning them by name:
- NtCompactKeys
- NtCompressKey
- NtFreezeRegistry
- NtInitializeRegistry
- NtLockRegistryKey
- NtQueryOpenSubKeysEx
- NtReplaceKey
- NtRestoreKey
- NtSaveKey
- NtSaveKeyEx
- NtSaveMergedKeys
- NtThawRegistry
- NtUnloadKey
- NtUnloadKey2
- NtUnloadKeyEx
Incorporating advanced features
Despite the fact that most power users are familiar with the basic registry operations (e.g., from using Regedit.exe), there are still some modifiers that can change the behavior of these operations, thereby complicating their implementation and potentially leading to interesting bugs. To use these modifiers, additional steps are often required, such as enabling registry virtualization, creating a transaction, or loading a differencing hive. When this is done, the information about the special key properties are encoded within the internal kernel structures, and the key handle itself is almost indistinguishable from other handles as seen by the user-mode application. When operating on such advanced keys, the logic for their handling is executed in the standard registry syscalls transparently to the user. The diagram below illustrates the general, conceptual control flow in registry-related system calls:

This is a very simplified outline of how registry syscalls work, but it shows that a function theoretically supporting one operation can actually hide many implementations that are dynamically chosen based on various factors. In terms of specifics, there are significant differences depending on the operation and whether it is a “read” or “write” one. For example, in “read” operations, the execution paths for transactional and non-transactional operations are typically combined into one that has built-in transaction support but can also operate without them. On the other hand, in “write” operations, normal and transactional operations are always performed differently, but there isn’t much code dedicated to layered keys (except for the so-called key promotion operations), since when writing to a layered key, the state of keys lower on the stack is usually not as important. As for the “Internal operation handler” area marked within the large rectangle with the dotted line, these are internal functions responsible for the core logic of a specific operation, and whose names typically begin with “Cm” instead of “Nt”. For example, for the NtDeleteKey syscall, the corresponding internal handler is CmDeleteKey, for NtQueryKey it is CmQueryKey, for NtEnumerateKey it is CmEnumerateKey, and so on.
In the following sections, we will take a closer look at each of the possible complications.
Predefined keys and symbolic links
Predefined keys were deprecated in 2023, so I won’t spend much time on them here. It’s worth mentioning that on modern systems, it wasn’t possible to create them in any way using the API, or even directly using syscalls. The only way to craft such a key in the registry was to create it in binary form in a controlled hive file and have it loaded via RegLoadAppKey or as a user hive. These keys had very strange semantics, both at the key node level (unusual encoding of _CM_KEY_NODE.ValueList) and at the kernel key body object level (non-standard value of _CM_KEY_BODY.Type). Due to the need to filter out these keys at an early stage of syscall execution, there are special helper functions whose purpose is to open the key by handle and verify whether it is or isn’t a predefined handle (CmObReferenceObjectByHandle and CmObReferenceObjectByName). Consequently, hunting for bugs related to predefined handles involved verifying whether each syscall used the above wrappers correctly, and whether there was some other way to perform an operation on this type of key while bypassing the type check. As I have mentioned, this is now just a thing of the past, as predefined handles in input hives are no longer supported and therefore do not pose a security risk to the system.
When it comes to symbolic links, this is a semi-documented feature that requires calling the RegCreateKeyEx function with the special REG_OPTION_CREATE_LINK flag to create them. Then, you need to set a value named “SymbolicLinkValue” and of type REG_LINK, which contains the target of the symlink as an absolute, internal registry path (Registry…) written using wide characters. From that point on, the link points to the specified path. However, it’s important to remember that traversing symbolic links originating from non-system hives is heavily restricted: it can only occur within a single “trust class” (e.g., between the user hive and user classes hive of the same user). As a result, links located in app hives are never fully functional, because each app hive resides in its own isolated trust class, and they cannot reference themselves either, as references to paths starting with “RegistryA” are blocked by the Windows kernel.
As for auditing symbolic links, they are generally resolved during the opening/creation of a key. Therefore, the analysis mainly involves the CmpParseKey function and lower-level functions called within it, particularly CmpGetSymbolicLinkTarget, which is responsible for reading the target of a given symlink and searching for it in existing registry structures. Issues related to symlinks can also be found in registry callbacks registered by third-party drivers, especially those that handle the RegNtPostOpenKey/RegNtPostCreateKey and similar operations. Correctly handling “reparse” return values and the multiple call loops performed by the NT Object Manager is not an easy feat to achieve.
Registry virtualization
Registry virtualization, introduced in Windows Vista, ensures backward compatibility for older applications that assume administrative privileges when using the registry. This mechanism redirects references between HKLMSoftware and HKU<SID>_ClassesVirtualStore subkeys transparently, allowing programs to “think” they write to the system hive even though they don’t have sufficient permissions for it. The virtualization logic, integrated into nearly every basic registry syscall, is mostly implemented by three functions:
- CmKeyBodyRemapToVirtualForEnum: Translates a real key inside a virtualized hive (HKLMSoftware) to a virtual key inside the VirtualStore of the user classes hive during read-type operations. This is done to merge the properties of both keys into a single state that is then returned to the caller.
- CmKeyBodyRemapToVirtual: Translates a real key to its corresponding virtual key, and is used in the key deletion and value deletion operations. This is done to delete the replica of a given key in VirtualStore or one of its values, instead of its real instance in the global hive.
- CmKeyBodyReplicateToVirtual: Replicates the entire key structure that the caller wants to create in the virtualized hive, inside of the VirtualStore.
All of the above functions have a complicated control flow, both in terms of low-level implementation (e.g., they implement various registry path conversions) and logically – they create new keys in the registry, merge the states of different keys into one, etc. As a result, it doesn’t really come as a big surprise that the code has been affected by many vulnerabilities. Triggering virtualization doesn’t require any special rights, but it does need a few conditions to be met:
- Virtualization must be specifically enabled for a given process. This is not the default behavior for 64-bit programs but can be easily enabled by calling the SetTokenInformation function with the TokenVirtualizationEnabled argument on the security token of the process.
- Depending on the desired behavior, the appropriate combination of VirtualSource/VirtualTarget/VirtualStore flags should be set in _CM_KEY_NODE.Flags. This can be achieved either through binary control over the hive or by setting it at runtime using the NtSetInformationKey call with the KeySetVirtualizationInformation argument.
- The REG_KEY_DONT_VIRTUALIZE flag must not be set in the _CM_KEY_NODE.VirtControlFlags field for a given key. This is usually not an issue, but if necessary, it can be adjusted either in the binary representation of the hive or using the NtSetInformationKey call with the KeyControlFlagsInformation argument.
- In specific cases, the source key must be located in a virtualizable hive. In such scenarios, the HKLMSoftwareMicrosoftDRM key becomes very useful, as it meets this condition and has a permissive security descriptor that allows all users in the system to create subkeys within it.
With regards to the first two points, many examples of virtualization-related bugs can be found in the Project Zero bug tracker. These reports include proof-of-concept code that correctly sets the appropriate flags. For simplicity, I will share that code here as well; the two C++ functions responsible for enabling virtualization for a given security token and registry key are shown below:
BOOL EnableTokenVirtualization(HANDLE hToken, BOOL bEnabled) {
DWORD dwVirtualizationEnabled = bEnabled;
return SetTokenInformation(hToken,
TokenVirtualizationEnabled,
&dwVirtualizationEnabled,
sizeof(dwVirtualizationEnabled));
}
BOOL EnableKeyVirtualization(HKEY hKey,
BOOL VirtualTarget,
BOOL VirtualStore,
BOOL VirtualSource) {
KEY_SET_VIRTUALIZATION_INFORMATION VirtInfo;
VirtInfo.VirtualTarget = VirtualTarget;
VirtInfo.VirtualStore = VirtualStore;
VirtInfo.VirtualSource = VirtualSource;
VirtInfo.Reserved = 0;
NTSTATUS Status = NtSetInformationKey(hKey,
KeySetVirtualizationInformation,
&VirtInfo,
sizeof(VirtInfo));
return NT_SUCCESS(Status);
}
And their example use:
HANDLE hToken;
HKEY hKey;
//
// Enable virtualization for the token.
//
if (!OpenProcessToken(GetCurrentProcess(), TOKEN_ALL_ACCESS, &hToken)) {
printf(“OpenProcessToken failed with error %un”, GetLastError());
return 1;
}
EnableTokenVirtualization(hToken, TRUE);
//
// Enable virtualization for the key.
//
hKey = RegOpenKeyExW(…);
EnableKeyVirtualization(hKey,
/*VirtualTarget=*/TRUE,
/*VirtualStore=*/ TRUE,
/*VirtualSource=*/FALSE);
Transactions
There are two types of registry transactions: KTM and lightweight. The former are transactions implemented on top of the tm.sys (Transaction Manager) driver, and they try to provide certain guarantees of transactional atomicity both during system run time and even across reboots. The latter, as the name suggests, are lightweight transactions that exist only in memory and whose task is to provide an easy and quick way to ensure that a given set of registry operations is applied atomically. As potential attackers, there are three parts of the interface that we are interested in the most: creating a transaction object, rolling back a transaction, and committing a transaction. The functions responsible for all three actions in each type of transaction are shown in the table below:
|
Operation |
KTM (API) |
KTM (system call) |
Lightweight (API) |
Lightweight (system call) |
|
Create transaction |
NtCreateTransaction |
– |
NtCreateRegistryTransaction |
|
|
Rollback transaction |
NtRollbackTransaction |
– |
NtRollbackRegistryTransaction |
|
|
Commit transaction |
NtCommitTransaction |
– |
NtCommitRegistryTransaction |
As we can see, the KTM has a public, documented API interface, which cannot be said for lightweight transactions that can only be used via syscalls. Their definitions, however, are not too difficult to reverse engineer, and they come down to the following prototypes:
NTSTATUS NtCreateRegistryTransaction(PHANDLE OutputHandle, ACCESS_MASK DesiredAccess, POBJECT_ATTRIBUTES ObjectAttributes, ULONG Reserved);
NTSTATUS NtRollbackRegistryTransaction(HANDLE Handle, ULONG Reserved);
NTSTATUS NtCommitRegistryTransaction(HANDLE Handle, ULONG Reserved);
Upon the creation of a transaction object, whether of type TmTransactionObjectType (KTM) or CmRegistryTransactionType (lightweight), its subsequent usage becomes straightforward. The transaction handle is passed to either the RegOpenKeyTransacted or the RegCreateKeyTransacted function, yielding a key handle. The key’s internal properties, specifically the key body structure, will reflect its transactional nature. Operations on this key proceed identically to the non-transactional case, using the same functions. However, changes are temporarily confined to the transaction context, isolated from the global registry view. Upon the completion of all transactional operations, the user may elect either to discard the changes via a rollback, or apply them atomically through a commit. From the developer’s perspective, this interface is undeniably convenient.
From an attack surface perspective, there’s a substantial amount of code underlying the transaction functionality. Firstly, the handler for each base operation includes code to verify that the key isn’t locked by another transaction, to allocate and initialize a UoW (unit of work) object, and then write it to the internal structures that describe the transaction. Secondly, to maintain consistency with the new functionality, the existing non-transactional code must first abort all transactions associated with a given key before it can be modified.
But that’s not the end of the story. The commit process itself is also complicated, as it must cleverly circumvent various registry limitations resulting from its original design. In 2023, most of the code responsible for KTM transactions was removed as a result of CVE-2023-32019, but there is still a second engine that was initially responsible for lightweight transactions and now handles all of them. It consists of two stages: “Prepare” and “Commit”. During the prepare stage, all steps that could potentially fail are performed, such as allocating all necessary cells in the target hive. Errors are allowed and correctly handled in the prepare stage, because the globally visible state of the registry does not change yet. This is followed by the commit stage, which is designed so that nothing can go wrong – it no longer performs any dynamic allocations or other complex operations, and its whole purpose is to update values in both the hive and the kernel descriptors so that transactional changes become globally visible. The internal prepare handlers for each individual operation have names starting with “CmpLightWeightPrepare” (e.g., CmpLightWeightPrepareAddKeyUoW), while the corresponding commit handlers start with “CmpLightWeightCommit” (e.g., CmpLightWeightCommitAddKeyUoW). These are the two main families of functions that are most interesting from a vulnerability research perspective. In addition to them, it is also worth analyzing the rollback functionality, which is used both when the rollback is requested directly by the user and when an error occurs in the prepare stage. This part is mainly handled by the CmpTransMgrFreeVolatileData function.
Layered keys
Layered keys are the latest major change of this type in the Windows Registry, introduced in 2016. They overturned many fundamental assumptions that had been in place until then. A given logical key no longer consists solely of one key node and a maximum of one active KCB, but of a whole stack of these objects: from the layer height of the given hive down to layer zero, which is the base hive. A key that has a key node may in practice be non-existent (if marked as a tombstone), and vice versa, a key without a key node may logically exist if there is an existing key with the same name lower in its stack. In short, this whole containerization mechanism has doubled the complexity of every single registry operation, because:
- Querying for information about a key has become more difficult, because instead of gathering information from just one key, it has to be potentially collected from many keys at once and combined into a coherent whole for the caller.
- Performing any “write” operations has become more difficult because before writing any information to the key at a given nesting level, you first need to make sure that the key and all its ancestors in a given hive exist, which is done in a complicated process called “key promotion”.
- Deleting and renaming a key has become more difficult, because you always have to consider and correctly handle higher-level keys that rely on the one you are modifying. This is especially true for Merge-Unbacked keys, which do not have their own representation and only reflect the state of the keys at a lower level. This also applies to ordinary keys from hives under HKLM and HKU, which by themselves have nothing to do with differencing hives, but as an integral part of the registry hierarchy, they also have to correctly support this feature.
- Performing security access checks on a key has become more challenging due to the need to accurately pinpoint the relevant security descriptor on the key stack first.
Overall, the layered keys mechanism is so complex that it could warrant an entire blog post (or several) on its own, so I won’t be able to explain all of its aspects here. Nevertheless, its existence will quickly become clear to anyone who starts reversing the registry implementation. The code related to this functionality can be identified in many ways, for example:
- By references to functions that initialize the key node stack / KCB stack objects (i.e., CmpInitializeKeyNodeStack, CmpStartKcbStack, and CmpStartKcbStackForTopLayerKcb),
- By dedicated functions that implement a given operation specifically on layered keys that end with “LayeredKey” (e.g., CmDeleteLayeredKey, CmEnumerateValueFromLayeredKey, CmQueryLayeredKey),
- By references to the KCB.LayerHeight field, which is very often used to determine whether the code is dealing with a layered key (height greater than zero) or a base key (height equal to zero).
I encourage those interested in further exploring this topic to read Microsoft’s Containerized Configuration patent (US20170279678A1), the “Registry virtualization” section in Chapter 10 of Windows Internals (Part 2, 7th Edition), as well as my previous blog post #6, where I briefly described many internal structures related to layered keys. All of these references are great resources that can provide a good starting point for further analysis.
When it comes to layered keys in the context of attack entry points, it’s important to note that loading custom differencing hives in Windows is not straightforward. As I wrote in blog post #4, loading this type of hive is not possible at all through any standard NtLoadKey-family syscall. Instead, it is done by sending an undocumented IOCTL 0x220008 to DeviceVRegDriver, which then passes this request on to an internal kernel function named CmLoadDifferencingKey. Therefore, the first obstacle is that in order to use this IOCTL interface, one would have to reverse engineer the layout of its corresponding input structure. Fortunately, I have already done it and published it in the blog post under the VRP_LOAD_DIFFERENCING_HIVE_INPUT name. However, a second, much more pressing problem is that communicating with the VRegDriver requires administrative rights, so it can only be used for testing purposes, but not in practical privilege escalation attacks.
So, what options are we left with? Firstly, there are potential scenarios where the exploit is packaged in a mechanism that legitimately uses differencing hives, e.g., an MSIX-packaged application running in an app silo, or a specially crafted Docker container running in a server silo. In such cases, we provide our own hives by design, which are then loaded on the victim’s system on our behalf when the malicious program or container is started. The second option is to simply ignore the inability to load our own hive and use one already present in the system. In a default Windows installation, many built-in applications use differencing hives, and the RegistryWC key can be easily enumerated and opened without any problems (unlike RegistryA). Therefore, if we launch a program running inside an app silo (e.g., Notepad) as a local user, we can then operate on the differencing hives loaded by it. This is exactly what I did in most of my proof-of-concept exploits related to this functionality. Of course, it is possible that a given bug will require full binary control over the differencing hive in order to trigger it, but this is a relatively rare case: of the 10 vulnerabilities I identified in this code, only two of them required such a high degree of control over the hive.
Alternative registry attack targets
The most crucial attack surface associated with the registry is obviously its implementation within the Windows kernel. However, other types of software interact with the registry in many ways and can be also prone to privilege escalation attacks through this mechanism. They are discussed in the following sections.
Drivers implementing registry callbacks
Another area where potential registry-related security vulnerabilities can be found is Registry Callbacks. This mechanism, first introduced in Windows XP and still present today, provides an interface for kernel drivers to log or interfere with registry operations in real-time. One of the most obvious uses for this functionality is antivirus software, which relies on registry monitoring. Microsoft, aware of this need but wanting to avoid direct syscall hooking by drivers, was compelled to provide developers with an official, documented API for this purpose.
From a technical standpoint, callbacks can be registered using either the CmRegisterCallback function or its more modern version, CmRegisterCallbackEx. The documentation for these functions serves as a good starting point for exploring the mechanism, as it seamlessly leads to the documentation of the callback function itself, and from there to the documentation of all the structures that describe the individual operations. Generally speaking, callbacks can monitor virtually any type of registry operation, both before (“pre” callbacks) and after (“post” callbacks) it is performed. They can be used to inspect what is happening in the system and log the details of specific events of interest. Callbacks can also influence the outcome of an operation. In “pre” notifications, they can modify input data or completely take control of the operation and return arbitrary information to the caller while bypassing the standard operation logic. During “post” notification handling, it is possible to influence both the status returned to the user and the output data. Overall, depending on the amount and types of operations supported in a callback, a completely error-free implementation can be really difficult to write. It requires excellent knowledge of the inner workings of the registry, as well as a very thorough reading of the documentation related to callbacks. The contracts that exist between the Windows kernel and the callback code can be very complicated, so in addition to the sources mentioned above, it’s also worth reading the entire separate series of seven articles detailing various callback considerations, titled Filtering Registry Calls.
Here are some examples of things that can go wrong in the implementation of callbacks:
- Standard user-mode memory access bugs. As per the documentation (refer to the table at the bottom of the Remarks section), pointers to output data received in “post” type callbacks contain the original user-mode addresses passed to the syscall by the caller. This means that if the callback wants to reference this data in any way, the only guarantee it has is that these pointers have been previously probed. However, it is still important to access this memory within a try/except block and to avoid potential double-fetch vulnerabilities by always copying the data to a kernel-mode buffer first before operating on it.
- A somewhat related but higher-level issue is excessive trust in the output data structure within “post” callbacks. The problem is that some registry syscalls return data in a strictly structured way, and since the “post” callback executes before returning to user mode, it might seem safe to trust that the output data conforms to its documented format (if one wants to use or slightly modify it). An example of such a syscall is NtQueryKey, which returns a specific structure for each of the several possible information classes. In theory, it would appear that a malicious program has not yet had the opportunity to modify this data, and it should still be valid when the callback executes. In practice, however, this is not the case, because the output data has already been copied to user-mode, and there may be a parallel user thread modifying it concurrently. Therefore, it is very important that if one wants to use the output data in the “post” callback, they must first fully sanitize it, assuming that it may be completely arbitrary and is as untrusted as any other input data.
- Moving up another level, it’s important to prevent confused deputy problems that exploit the fact that callback code runs with kernel privileges. For example, if a callback wanted to redirect access to certain registry paths to another location, and it used the ZwCreateKey call without the OBJ_FORCE_ACCESS_CHECK flag to do so, it would allow an attacker to create keys in locations where they normally wouldn’t have access.
- Bugs in the emulation of certain operations in “pre”-type callbacks. If a callback decides to handle a given request on its own and signal this to the kernel by returning the STATUS_CALLBACK_BYPASS code, it is responsible for filling all important fields in the corresponding REG_XXX_KEY_INFORMATION structure so that, in accordance with the expected syscall behavior, the output data is correctly returned to the caller (source: “When a registry filtering driver’s RegistryCallback routine receives a pre-notification […]” and “Alternatively, if the driver changes a status code from failure to success, it might have to provide appropriate output parameters.”).
- Bugs in “post”-type callbacks that change an operation’s status from success to failure. If we want to block an operation after it has already been executed, we must remember that it has already occurred, with all its consequences and side effects. To successfully pretend that it did not succeed, we would have to reverse all its visible effects for the user and release the resources allocated for this purpose. For some operations, this is very difficult or practically impossible to do cleanly, so I would personally recommend only blocking operations at the “pre” stage and refraining from trying to influence their outcome at the “post” stage (source: “If the driver changes a status code from success to failure, it might have to deallocate objects that the configuration manager allocated.”).
- Challenges presented by error handling within “post”-type callbacks. As per the documentation, the kernel only differentiates between a STATUS_CALLBACK_BYPASS return value and all others, which means that it doesn’t really discern callback success or failure. This is somewhat logical since, at this stage, there isn’t a good way to handle failures – the operation has already been performed. On the other hand, it may be highly unintuitive, as the Windows kernel idiom “if (!NT_SUCCESS(Status)) { return Status; }” becomes ineffective here. If an error is returned, it won’t propagate to user mode, and will only cause premature callback exit, potentially leaving some important operations unfinished. To address this, you should design “post” callbacks to be inherently fail-safe (e.g., include no dynamic allocations), or if this isn’t feasible, implement error handling cautiously, ensuring that minor operation failures don’t compromise the callback’s overall logical/security guarantees.
- Issues surrounding the use of a key object pointer passed to the callback, in one of a few specific scenarios where it can have a non-NULL value but not point to a valid key object. This topic is explored in a short article in Microsoft Learn: Invalid Key Object Pointers in Registry Notifications.
- Issues in open/create operation callbacks due to missing or incorrect handling of symbolic links and other redirections, which are characterized by the return values STATUS_REPARSE and STATUS_REPARSE_GLOBAL.
- Bugs that result from a lack of transaction support where it is needed. This could be an incorrect assumption that every operation performed on the registry is non-transactional and its effect is visible immediately, and not only after the transaction is committed. The API function that is used to retrieve the transaction associated with a given key (if it exists) during callback execution is CmGetBoundTransaction.
- Issues arising from using the older API version, CmCallbackGetKeyObjectID, instead of the newer CmCallbackGetKeyObjectIDEx. The older version has some inherent problems discussed in the documentation, such as returning an outdated key path if the key name has been changed by an NtRenameKey operation.
- Issues stemming from an overreliance on the CmCallbackGetKeyObjectID(Ex) function to retrieve a key’s full path. A local user can cause these functions to deterministically fail by creating and operating on a key with a path length exceeding 65535 bytes (the maximum length of a string represented by the UNICODE_STRING structure). This can be achieved using the key renaming trick described in CVE-2022-37990, and results in the CmCallbackGetKeyObjectID(Ex) function returning the STATUS_INSUFFICIENT_RESOURCES error code. This is problematic because the documentation for this function does not mention this error code, and there is no way to defend against it from the callback’s perspective. The only options are to avoid relying on retrieving the full key path altogether, or to implement a defensive fallback plan if this operation fails.
- Logical bugs arising from attempts to block access to certain registry keys by path, but neglecting the key rename operation, which can change the key’s name dynamically and bypass potential filtering logic in the handling of the open/create operations. Notably, it’s difficult to blame developers for such mistakes, as even the official documentation discourages handling NtRenameKey operations, citing its high complexity (quote: “Several registry system calls are not documented because they are rarely used […]”).
As we can see, developers using these types of callbacks can fall into many traps, and the probability of introducing a bug increases with the complexity of the callback’s logic.
As a security researcher, there are two approaches to enumerating this attack surface to find vulnerable callbacks: static and dynamic. The static approach involves searching the file system (especially C:Windowssystem32drivers) for the “CmRegisterCallback” string, as every driver that registers a callback must refer to this function or its “Ex” equivalent. As for the dynamic approach, the descriptors of all callbacks in the system are linked together in a doubly-linked list that begins in the global nt!CallbackListHead object. Although the structure of these descriptors is undocumented, my analysis indicates that the pointer to the callback function is located at offset 0x28 in Windows 11. Therefore, all callbacks registered in the system at a given moment can be listed using the following WinDbg command:
0: kd> !list -x “dqs @$extret+0x28 L1″ CallbackListHead
fffff801`c42f6cd8 fffff801`c42f6cd0 nt!CmpPreloadedHivesList
ffffdc88`d377e418 fffff801`56a48df0 WdFilter!MpRegCallback
ffffdc88`d8610b38 fffff801`59747410 applockerfltr!SmpRegistryCallback
ffffdc88`d363e118 fffff801`57a05dd0 UCPD+0x5dd0
ffffdc88`ed11d788 fffff801`c3c2ba50 nt!VrpRegistryCallback
ffffdc88`d860c758 fffff801`597510c0 bfs!BfsRegistryCallback
As shown, even on a clean Windows 11 system, the operating system and its drivers register a substantial number of callbacks. In the listing above, the first line of output can be ignored, as it refers to the nt!CallbackListHead object, which is the beginning of the list and not a real callback descriptor. The remaining functions are associated with the following modules:
- WdFilter!MpRegCallback: a callback registered by Windows Defender, the default antivirus engine running on Windows.
- applockerfltr!SmpRegistryCallback: a callback registered by the Smartlocker Filter Driver, which is one of the drivers that implement the AppLocker/SmartLocker functionality at the kernel level.
- UCPD+0x5dd0: a callback associated with the UCPD.sys driver, which expands to “User Choice Protection Driver”. This is a module that prevents third-party software from modifying the default application settings for certain file types and protocols, such as web browsers and PDF readers. As we can infer from the format of this symbol and its unresolved name, Microsoft does not currently provide PDB debug symbols for the executable image, but some information online indicates that such symbols were once available for older builds of the driver.
- nt!VrpRegistryCallback: a callback implemented by the VRegDriver, which is part of the core Windows kernel executable image, ntoskrnl.exe. It plays a crucial role in the system, as it is responsible for redirecting key references to their counterparts within differencing hives for containerized processes. It is likely the most interesting and complex callback registered by default in Windows.
- bfs!BfsRegistryCallback: the callback is a component of the Brokering File System driver. It is primarily responsible for supporting secure file access for applications running in an isolated environment (AppContainers). However, it also has a relatively simple registry callback that supports key opening/creation operations. It is not entirely clear why the functionality wasn’t simply incorporated into the VrpRegistryCallback, which serves a very similar purpose.
In my research, I primarily focused on reviewing the callback invocations in individual registry operations (specifically calls to the CmpCallCallBacksEx function), and on the correctness of the VrpRegistryCallback function implementation. As a result, I discovered CVE-2023-38141 in the former area, and three further bugs in the VRegDriver (CVE-2023-38140, CVE-2023-36803 and CVE-2023-36576). These reports serve as a very good example of the many types of problems that can occur in registry callbacks.
Privileged registry clients: programs and drivers
The final attack target related to the registry are the highly privileged users of this interface, that is, user-mode processes running with administrator/system rights, and kernel drivers that operate on the registry. The registry is a shared resource by design, and apart from app hives mounted in the special RegistryA key, every program in the system can refer to any active key as long as it has the appropriate permissions. And for a malicious user, this means that they can try to exploit weaknesses exhibited by other processes when interacting with the registry, and secondly, they can try to actively interfere with them. I can personally imagine two main types of issues related to incorrect use of the registry, and both of them are quite high-level by nature.
The first concern is related to the fact that the registry, as a part of the NT Object Manager model, undergoes standard access control through security access checks. Each registry key is mandatorily assigned a specific security descriptor. Therefore, as the name implies, it is crucial for system security that each key’s descriptor has the minimum permissions required for proper functionality, while aligning with the author’s intended security model for the application.
From a technical perspective, a specific security descriptor for a given key can be set either during its creation through the lpSecurityAttributes argument of RegCreateKeyExW, or separately by calling the RegSetKeySecurity API. If no descriptor is explicitly set, the key assumes a default descriptor based largely on the security settings of its parent key. This model makes sense from a practical standpoint. It allows most applications to avoid dealing with the complexities of custom security descriptors, while still maintaining a reasonable level of security, as high-level keys in Windows typically have well-configured security settings. Consider the well-known HKLMSoftware tree, where Win32 applications have stored their global settings for many years. The assumption is that ordinary users have read access to the global configuration within that tree, but only administrators can write to it. If an installer or application creates a new subkey under HKLMSoftware without explicitly setting a descriptor, it inherits the default security properties, which is sufficient in most cases.
However, certain situations require extra care to properly secure registry keys. For example, if an application stores highly sensitive data (e.g., user passwords) in the registry, it is important to ensure that both read and write permissions are restricted to the smallest possible group of users (e.g., administrators only). Additionally, when assigning custom security descriptors to keys in global system hives, you should exercise caution to avoid inadvertently granting write permissions to all system users. Furthermore, if a user has KEY_CREATE_LINK access to a global key used by higher-privileged processes, they can create a symbolic link within it, potentially resulting in a “confused deputy” problem and the ability to create registry keys under any path. In summary, for developers creating high-privilege code on Windows and utilizing the registry, it is essential to carefully handle the security descriptors of the keys they create and operate on. From a security researcher’s perspective, it could be useful to develop tooling to list all keys that allow specific access types to particular groups in the system and run it periodically on different Windows versions and configurations. This approach can lead to some very easy bug discoveries, as it doesn’t require any time spent on reverse engineering or code auditing.
The second type of issue is more subtle and arises because a single “configuration unit” in the registry sometimes consists of multiple elements (keys, values) and must be modified atomically to prevent an inconsistent state and potential vulnerabilities. For such cases, there is support for transactions in the registry. If a given process manages a configuration that is critical to system security and in which different elements must always be consistent with each other, then making use of the Transacted Registry (TxR) is practically mandatory. A significantly worse, though somewhat acceptable solution may be to implement a custom rollback logic, i.e., in the event of a failure of some individual operation, manually reversing the changes that have been applied so far. The worst case scenario is when a privileged program does not realize the seriousness of introducing partial changes to the registry, and implements its logic in a way typical of using the API in a best-effort manner, i.e.: calling Win32 functions as long as they succeed, and when any of them returns an error, then simply passing it up to the caller without any additional cleanup.
Let’s consider this bug class on the example of a hypothetical service that, through some local inter-process communication interface, allows users to register applications for startup. It creates a key structure under the HKLMSoftwareCustomAutostart<Application Name> path, and for each such key it stores two values: the command line to run during system startup (“CommandLine”), and the username with whose privileges to run it (“UserName”). If the username value does not exist, it implicitly assumes that the program should start with system rights. Of course, the example service intends to be secure, so it only allows setting the username to the one corresponding to the security token of the requesting process. Operations on the registry take place in the following order:
- Create a new key named HKLMSoftwareCustomAutostart<Application Name>,
- Set the “CommandLine” value to the string provided by the client,
- Set the “UserName” value to the string provided by the client.
The issue with this logic is that it’s not transactional – if an error occurs, the execution simply aborts, leaving the partial state behind. For example, if operation #3 fails for any reason, an entry will be added to the autostart indicating that a controlled path should be launched with system rights. This directly leads to privilege escalation and was certainly not the developer’s intention. One might wonder why any of these operations would fail, especially in a way controlled by an attacker. The answer is simple and was explained in the “Susceptibility to mishandling OOM conditions” section. A local attacker has at least two ways of influencing the success or failure of registry operations in the system: by filling the space of the hive they want to attack (if they have write access to at least one of its keys) or by occupying the global registry quota in memory, represented by the global nt!CmpGlobalQuota variable. Unfortunately, finding such vulnerabilities is more complicated than simply scanning the entire registry for overly permissive security descriptors. It requires identifying candidates of registry operations in the system that have appropriate characteristics (high privilege process, lack of transactionality, sensitivity to a partial/incomplete state), and then potentially reverse-engineering the specific software to get a deeper understanding of how it interacts with the registry. Tools like Process Monitor may come in handy at least in the first part of the process.
One example of a vulnerability related to the incorrect guarantee of atomicity of system-critical structures is CVE-2024-26181. As a result of exhausting the global registry quota, it could lead to permanent damage to the HKLMSAM hive, which stores particularly important information about users in the system, their passwords, group memberships, etc.
Vulnerability primitives
In this chapter, we will focus on classifying registry vulnerabilities based on the primitives they offer, and briefly discuss their practical consequences and potential exploitation methods.
Pool memory corruption
Pool memory corruption is probably the most common type of low-level vulnerability in the Windows kernel. In the context of the registry, this bug class is somewhat rarer than in other ring-0 components, but it certainly still occurs and is entirely possible. It manifests in its most “pure” form when the corruption happens within an auxiliary object that is temporarily allocated on the pools to implement a specific operation. One such example case is a report concerning three vulnerabilities—CVE-2022-37990, CVE-2022-38038, and CVE-2022-38039—all stemming from a fairly classic 16-bit integer overflow when calculating the length of a dynamically allocated buffer. Another example is CVE-2023-38154, where the cause of the buffer overflow was slightly more intricate and originated from a lack of error handling in one of the functions responsible for recovering the hive state from LOG files.
The second type of pool memory corruption that can occur in the registry is problems managing long-lived objects that are used to cache some information from the hive mapping in more readily accessible pool memory — such as those described in post #6. In this case, we are usually dealing with UAF-type conditions, like releasing an object while there are still some active references to it. If I had to point to one object that could be most prone to this type of bug, it would probably be the Key Control Block, which is reference counted, used by the implementation of almost every registry syscall, and for which there are some very strong invariants critical for memory safety (e.g., the existence of only one KCB for a particular key in the global KCB tree). One issue related to KCBs was CVE-2022-44683, which resulted from incorrect handling of predefined keys in the NtNotifyChangeMultipleKeys system call.
Another, slightly different category of UAFs on pools are situations in which this type of condition is not a direct consequence of a vulnerability, but more of a side effect. Let’s take security descriptors as an example: they are located in the hive space, but the kernel also maintains a cache reflecting the state of these descriptors on the kernel pools (in _CMHIVE.SecurityCache and related fields). Therefore, if for some reason a security descriptor in the hive is freed prematurely, this problem will also be automatically reflected in the cache, and some keys may start to have a dangling KCB.CachedSecurity pointer set to the released object. I have taken advantage of this fact many times in my reports to Microsoft, because it was very useful for reliably triggering crashes. While generating a bugcheck based on the UAF of the _CM_KEY_SECURITY structure in the hive is possible, it is much more convoluted than simply turning on the Special Pool mechanism and making the kernel refer to the cached copy of the security descriptor (a few examples: CVE-2023-23421, CVE-2023-35382, CVE-2023-38139). In some cases, exploiting memory corruption on pools may also offer some advantages over exploiting hive-based memory corruption, so it is definitely worth remembering this behavior for the future.
When it comes to the strictly technical aspects of kernel pool exploitation, I won’t delve into it too deeply here. I didn’t specifically focus on it in my research, and there aren’t many interesting registry-specific details to mention in this context. If you are interested to learn more about this topic, please refer to the resources available online.
Hive memory corruption
The second type of memory corruption encountered in the registry is hive-based memory corruption. This class of bugs is unique to the registry and is based on the fact that data stored in hives serves a dual role. It stores information persistently on disk, but it also works as the representation of the hive in memory in the exact same form. The data is then operated on using C code through pointers, helper functions like memcpy, and so on. Given all this, it doesn’t come as a surprise that classic vulnerabilities such as buffer overflows or use-after-free can also occur within this region.
So far, during my research, I have managed to find 17 hive-based memory corruption issues, which constitutes approximately 32% of all 53 vulnerabilities that have been fixed by Microsoft in security bulletins. The vast majority of them were related to just two mechanisms – reference counting security descriptors and operating on subkey lists – but there were also cases of bugs related to other types of objects.
I have started using the term “inconsistent hive state”, referring to any situation where the regf format state either ceases to be internally consistent or stops accurately reflecting cached copies of the same data within other kernel objects. I described one such issue here, where the _CM_BIG_DATA.Count field stops correctly corresponding to the _CM_KEY_VALUE.DataLength field for the same registry value. However, despite this specific behavior being incorrect, according to both my analysis and Microsoft’s, it doesn’t have any security implications for the system. In this context, the term “hive-based memory corruption” denotes a slightly narrower group of issues that not only allow reaching any inconsistent state but specifically enable overwriting valid regf structures with attacker-controlled data.
The general scheme for exploiting hive-based memory corruption closely resembles the typical exploitation of any other memory corruption. The attacker’s initial objective is to leverage the available primitive and manipulate memory allocations/deallocations to overwrite a specific object in a controlled manner. On modern systems, achieving this stage reliably within the heap or kernel pools can be challenging due to allocator randomization and enforced consistency checks. However, the cell allocator implemented by the Windows kernel is highly favorable for the attacker: it lacks any safeguards, and its behavior is entirely deterministic, which greatly simplifies this stage of exploit development. One could even argue that, given the properties of this allocator, virtually any memory corruption primitive within the regf format can be transformed into complete control of the hive in memory with some effort.
With this assumption, let’s consider what to do next. Even if we have absolute control over all the internal data of the mapped hive, we are still limited to its mapping in memory, which in itself does not give us much. The question arises as to how we can “escape” from this memory region and use hive memory corruption to overwrite something more interesting, like an arbitrary address in kernel memory (e.g., the security token of our process).
First of all, it is worth noting that such an escape is not always necessary – if the attack is carried out in one of the system hives (SOFTWARE, SYSTEM, etc.), we may not need to corrupt the kernel memory at all. In this case, we could simply perform a data-only attack and modify some system configuration, grant ourselves access to important system keys, etc. However, with many bugs, attacking a highly privileged hive is not possible. Then, the other option available to the attacker is to modify one of the cells to break some invariant of the regf format, and cause a second-order side effect in the form of a kernel pool corruption. Some random ideas are:
- Setting too long a key name or inserting the illegal character ” into the name,
- Creating a fake exit node key,
- Corrupting the binary structure of a security descriptor so that the internal APIs operating on them start misbehaving,
- Crafting a tree structure within the hive with a depth greater than the maximum allowed (512 levels of nesting),
- … and many, many others.
However, during experiments exploring practical exploitation, I discovered an even better method that grants an attacker the ability to perform reliable arbitrary read and write operations in kernel memory—the ultimate primitive. This method exploits the behavior of 32-bit cell index values, which exhibit unusual behavior when they exceed the hive’s total size. I won’t elaborate on the full technique here, but for those interested, I discussed it during my presentation at the OffensiveCon conference in May 2024. The subject of exploiting hive memory corruption will be also covered in detail in its own dedicated blog post in the future.
Invalid cell indexes
This is a class of bugs that manifests directly when an incorrect cell index appears in an object—either in a cell within the hive or in a structure on kernel pools, like KCB. These issues can be divided into three subgroups, depending on the degree of control an attacker can gain over the cell index.
Cell index 0xFFFFFFFF (HCELL_NIL)
This is a special marker that indicates that a given structure member/variable of type HCELL_INDEX doesn’t point to any specific cell, which is equivalent to a NULL pointer in C. There are many situations where the value 0xFFFFFFFF (in other words, -1) is used and even desired, e.g. to signal that an optional object doesn’t exist and shouldn’t be processed. The kernel code is prepared for such cases and correctly checks whether a given cell index is equal to this marker before operating on it. However, problems can arise when the value ends up in a place where the kernel always expects a valid index. Any mandatory field in a specific object can be potentially subject to this problem, such as the _CM_KEY_NODE.Security field, which must always point to a valid descriptor and should never be equal to -1 (other than for exit nodes).
Some examples of such vulnerabilities include:
- CVE-2023-21772: an unexpected value of -1 being set in _CM_KEY_NODE.Security due to faulty logic in the registry virtualization code, which first freed the old descriptor and only then attempted to allocate a new one, which could fail, leaving the key without any assigned security descriptor.
- CVE-2023-35357: an unexpected value of -1 being set in KCB.KeyCell, because the code assumed that it was operating on a physically existing base key, while in practice it could operate on a layered key with Merge-Unbacked semantics, which does not have its own key node, but relies solely on key nodes at lower levels of the key stack.
- CVE-2023-35358: another case of an unexpected value of -1 being set in KCB.KeyCell, while the kernel expected that at least one key in the given key node stack would have an allocated key node object. The source of the problem here was incorrect integration of transactions and differencing hives.
When such a problem occurs, it always manifests by the value -1 being passed as the cell index to the HvpGetCellPaged function. For decades, this function completely trusted its parameters, assuming that the input cell index would always be within the bounds of the given hive. Consequently, calling HvpGetCellPaged with a cell index of 0xFFFFFFFF would result in the execution of the following code:
_CELL_DATA *HvpGetCellPaged(_HHIVE *Hive, HCELL_INDEX Index) {
_HMAP_ENTRY *Entry = &Hive->Storage[1].Map->Directory[0x3FF]->Table[0x1FF];
return (Entry->PermanentBinAddress & (~0xF)) + Entry->BlockOffset + 0xFFF + 4;
}
In other words, the function would refer to the Volatile (1) map cell, and within it, to the last element of the Directory and then the Table arrays. Considering the “small dir” optimization described in post #6, it becomes clear that this cell map walk could result in an out-of-bounds memory access within the kernel pools (beyond the boundaries of the _CMHIVE structure). Personally, I haven’t tried to transform this primitive into anything more useful, but it seems evident that with some control over the kernel memory around _CMHIVE, it should theoretically be possible to get the HvpGetCellPaged function to return any address chosen by the attacker. Further exploitation prospects would largely depend on the subsequent operations that would be performed on such a fake cell, and the extent to which a local user could influence them. In summary, I’ve always considered these types of bugs as “exploitable on paper, but quite difficult to exploit in practice.”
Ultimately, none of this matters much, because it seems that Microsoft noticed a trend in these vulnerabilities and, in July 2023, added a special condition to the HvpGetCellFlat and HvpGetCellPaged functions:
if (Index == HCELL_NIL) {
KeBugCheckEx(REGISTRY_ERROR, 0x32, 1, Hive, 0xFFFFFFFF);
}
This basically means that the specific case of index -1 has been completely mitigated, since rather than allowing any chance of exploitation, the system now immediately shuts down with a Blue Screen of Death. As a result, the bug class no longer has any security implications. However, I do feel a bit disappointed – if Microsoft deemed the check sufficiently important to add to the code, they could have made it just a tiny bit stronger, for example:
if ((Index & 0x7FFFFFFF) >= Hive->Storage[Index >> 31].Length) {
KeBugCheckEx(…);
}
The above check would reject all cell indexes exceeding the length of the corresponding storage type, and it is exactly what the HvpReleaseCellPaged function currently does. Checking this slightly stronger condition in one fell swoop would handle invalid indexes of -1 and completely mitigate the previously mentioned technique of out-of-bounds cell indexes. While not introduced yet, I still secretly hope that it will happen one day… 🙂
Dangling (out-of-date) cell indexes
Another group of vulnerabilities related to cell indexes are cases where, after a cell is freed, its index remains in an active cell within the registry. Simply put, these are just the cell-specific use-after-free conditions, and so the category very closely overlaps with the previously described hive-based memory corruption.
Notable examples of such bugs include:
- CVE-2022-37988: Caused by the internal HvReallocateCell function potentially failing when shrinking an existing cell, which its caller assumed was impossible.
- CVE-2023-23420: A bug in the transactional key rename operation could lead to a dangling cell index in a key’s subkey list, pointing to a freed key node.
- CVE-2024-26182: Caused by mishandling a partial success situation where an internal function might successfully perform some operations on the hive (reallocate existing subkey lists) but ultimately return an error code, causing the caller to skip updating the _CM_KEY_NODE.SubKeyLists[…] field accordingly.
- All use-after-free vulnerabilities in security descriptors due to incorrect reference counting: CVE-2022-34707, CVE-2023-28248, CVE-2023-35356, CVE-2023-35382, CVE-2023-38139, and CVE-2024-43641.
In general, UAF bugs within the hive are powerful primitives that can typically be exploited to achieve total control over the hive’s internal data. The fact that both exploits I wrote to demonstrate practical exploitation of hive memory corruption vulnerabilities fall into this category (CVE-2022-34707, CVE-2023-23420) can serve as anecdotal evidence of this statement.
Fully controlled/arbitrary cell indexes
The last type of issues where cell indexes play a major role are situations in which the user somehow obtains full control over the entire 32-bit index value, which is then referenced as a valid cell by the kernel. Notably, this is not about some second-order effect of hive memory corruption, but vulnerabilities where this primitive is the root cause of the problem. Such situations happen relatively rarely, but there have been at least two such cases in the past:
- CVE-2022-34708: missing verification of the _CM_KEY_SECURITY.Blink field in the CmpValidateHiveSecurityDescriptors function for the root security descriptor in the hive,
- CVE-2023-35356: referencing the _CM_KEY_NODE.ValueList.List field in a predefined key, in which the ValueList structure has completely different semantics, and its List field can be set to an arbitrary value.
Given that the correctness of cell indexes is a fairly obvious requirement known to Microsoft kernel developers, they pay close attention to verifying them thoroughly. For this reason, I think that the chance we will have many more such bugs in the future is slim. As for their exploitation, they may seem similar in nature to the way hive memory corruption can be exploited with out-of-bounds cell indexes, but in fact, these are two different scenarios. With hive-based memory corruption, we can dynamically change the value of a cell index multiple times as needed, and here, we would only have one specific 32-bit value at our disposal. If, in a hypothetical vulnerability, some interesting operations were performed on such a controlled index, I would probably still reduce the problem to the typical UAF case, try to obtain full binary control over the hive, and continue from there.
Low-level information disclosure (memory, pointers)
Since the registry code is written in C and operates with kernel privileges, and additionally has not yet been completely rewritten to use zeroing ExAllocatePool functions, it is natural that it may be vulnerable to memory disclosure issues when copying output data to user-mode. The most canonical example of such a bug was CVE-2023-38140, where the VrpPostEnumerateKey function (one of the sub-handlers of the VRegDriver registry callback) allocated a buffer on kernel pools with a user-controlled length, filled it with some amount of data – potentially less than the buffer size – and then copied the entire buffer back to user mode, including uninitialized bytes at the end of the allocation.
However, besides this typical memory disclosure scenario, it is worth noting two more things in the context of the registry. One of them is that, as we know, the registry operates not only on memory but also on various files on disk, and therefore the filesystem becomes another type of data sink where data leakage can also occur. And so, for example, in CVE-2022-35768, kernel pool memory could be disclosed directly to the hive file due to an out-of-bounds read vulnerability, and in CVE-2023-28271, both uninitialized data and various kernel-mode pointers were leaked to KTM transaction log files.
The second interesting observation is that the registry implementation does not have to be solely the source of the data leak, but can also be just a medium through which it happens. There is a certain group of keys and values that are readable by ordinary users and initialized with binary data by the kernel and drivers using ZwSetValueKey and similar functions. Therefore, there is a risk that some uninitialized data may leak through this channel, and indeed during my Bochspwn Reloaded research in 2018, I identified several instances of such leaks, such as CVE-2018-0898, CVE-2018-0899, and CVE-2018-0900.
Broken security guarantees, API contracts and common sense assumptions
Besides maintaining internal consistency and being free of low-level bugs, it’s also important that the registry behaves logically and predictably, even under unusual conditions. It must adhere to the overall security model of Windows NT, operate in accordance with its public documentation, and behave in a way that aligns with common sense expectations. Failure to do so could result in various problems in the client software that interacts with it, but identifying such deviations from expected behavior can be challenging, as it requires deep understanding of the interface’s high-level principles and the practical implications of violating them.
In the following subsections, I will discuss a few examples of issues where the registry’s behavior was inconsistent with documentation, system architecture, or common sense.
Security access rights enforcement
The registry implementation must enforce security checks, meaning it must verify appropriate access rights to a key when opening it, and then again when performing specific operations on the obtained handle. Generally, the registry manages this well in most cases. However, there were two bugs in the past that allowed a local user to perform certain operations that they theoretically didn’t have sufficient permissions for:
- CVE-2023-21750: Due to a logic bug in the CmKeyBodyRemapToVirtual function (related to registry virtualization), it was possible to delete certain keys within the HKLMSoftware hive with only KEY_READ and KEY_SET_VALUE rights, without the normally required DELETE right.
- CVE-2023-36404: In this case, it was possible to gain access to the values of certain registry keys despite lacking appropriate rights. The attack itself was complex and required specific circumstances: loading a differencing hive overlaid on a system hive with a specially crafted key structure, and then having a system component create a secret key in that system hive. Because of the fact that the handle to the layered key would be opened earlier (and the security access check would be performed at that point in time), creating a new key at a lower level with more restricted permissions wouldn’t be considered later, leading to potential information disclosure.
As shown, both these bugs were directly related to incorrect or missing permissions verification, but they weren’t particularly attractive in terms of practical attacks. A much more appealing bug was CVE-2019-0881, discovered in registry virtualization a few years earlier by James Forshaw. That vulnerability allowed unprivileged users to read every registry value in the system regardless of the user’s privileges, which is about as powerful as a registry infoleak can get.
Confused deputy problems with predefined keys
Predefined keys probably don’t need any further introduction at this point in the series. In this specific case of the confused deputy problem, the bug report for CVE-2023-35633 captures the essence of the issue well: if a local attacker had binary control over a hive, they could cause the use of an API like RegOpenKeyExW on any key within that hive to return one of the predefined pseudo-handles like HKEY_LOCAL_MACHINE, HKEY_CURRENT_USER, etc., instead of a normal handle to that key. This behavior was undocumented and unexpected for developers using registry in their code. Unsurprisingly, finding a privileged process that did something interesting on a user-controlled hive wasn’t that hard, and it turned out that there was indeed a service in Windows that opened a key inside the HKCU of each logged-in user, and recursively set permissive access rights on that key. By abusing predefined handles, it was possible to redirect the operation and grant ourselves full access to one of the global keys in the system, leading to a fairly straightforward privilege escalation. If you are interested in learning more about the bug and its practical exploitation, please refer to my Windows Registry Deja Vu: The Return of Confused Deputies presentation from CONFidence 2024. In many ways, this attack was a resurrection of a similar confused deputy problem, CVE-2010-0237, which I had discovered together with Gynvael Coldwind. The main difference was that at that time, the redirection of access to keys was achieved via symbolic links, a more obvious and widely known mechanism.
Atomicity of KTM transactions
The main feature of any transaction implementation is that it should guarantee atomicity – that is, either apply all changes being part of the transaction, or none of them. Imagine my surprise then, when I discovered that the registry transaction implementation integrated with the KTM did not guarantee atomicity at all, but merely tried really hard to maintain it. The main problem was that it wasn’t designed to handle OOM errors (for example, when a hive was completely full) and, as a result, when such a problem occurred in the middle of committing a transaction, there was no good way to reverse the changes already applied. The Configuration Manager falsely returned a success code to the caller, while retrying to commit the remaining part of the transaction every 30 seconds, hoping that some space would free up in the registry in the meantime, and the operations would eventually succeed. This type of behavior obviously contradicted both the documentation and common sense about how transactions should work.
I reported this issue as CVE-2023-32019, and Microsoft fixed it by completely removing a large part of the code that implemented this functionality, as it was simply impossible to fix correctly without completely redesigning it from scratch. Fortunately, in Windows 10, an alternative transaction implementation for the registry called lightweight transactions was introduced, which was designed correctly and did not have the same problem. As a result, a decision was made to internally redirect the handling of KTM transactions within the Windows kernel to the same engine that is responsible for lightweight transactions.
Containerized registry escapes
The general goal of differencing hives and layered keys is to implement registry containerization. This mechanism creates an isolated registry view for a specific group of processes, without direct access to the host registry (a sort of “chroot” for the Windows registry). Unfortunately, there isn’t much official documentation on this topic, and it’s particularly difficult to find information on whether this type of containerization is a Microsoft-supported security boundary that warrants fixes in the monthly security bulletins. I think it is reasonable to expect that since the mechanism is used to isolate the registry in well supported use-cases (such as running Docker containers), it should ideally not be trivial to bypass, but I was unable to find any official statement to support or refute this assumption.
When I looked further into it, I discovered that the redirection of registry calls within containerized environments was managed by registry callbacks, specifically one called VrpRegistryCallback. While callbacks do indeed seem well suited for this purpose, the devil is in the details – specifically, error handling. I found at least two ways a containerized application could trigger an error during the execution of the internal VrpPreOpenOrCreate/VrpPostOpenOrCreate handlers. This resulted in exiting the callback prematurely while an important part of the redirection logic still hadn’t been executed, and consequently led to the process gaining access to the host’s registry view. Additionally, I found that another logical bug allowed access to the host’s registry through differencing hives associated with other active containers in the system.
As I mentioned, I wasn’t entirely clear on the state of Microsoft’s support for this mechanism, but luckily I didn’t have to wonder for too long. It turned out that James Forshaw had a similar dilemma and managed to reach an understanding with the vendor on the matter, which he described in his blog post.
After much back and forth with various people in MSRC a decision was made. If a container escape works from a non-administrator user, basically if you can access resources outside of the container, then it would be considered a privilege escalation and therefore serviceable.
[…]
Microsoft has not changed the MSRC servicing criteria at the time of writing. However, they will consider fixing any issue which on the surface seems to escape a Windows Server Container but doesn’t require administrator privileges. It will be classed as an elevation of privilege.
Eventually, I reported all three bugs in one report, and Microsoft fixed them shortly after as CVE-2023-36576. I particularly like the first issue described in the report (the bug in VrpBuildKeyPath), as it makes a very interesting example of how a theoretically low-level issue like a 16-bit integer overflow can have the high-level consequences of a container escape, without any memory corruption being involved.
Adherence to official key and value name length limits
The constraints on the length of key and value names are quite simple. Microsoft defines the maximum values on a dedicated documentation page called Registry Element Size Limits:
|
Registry element |
Size limit |
|
Key name |
255 characters. The key name includes the absolute path of the key in the registry, always starting at a base key, for example, HKEY_LOCAL_MACHINE. |
|
Value name |
16,383 characters. Windows 2000: 260 ANSI characters or 16,383 Unicode characters. |
Admittedly, the way this is worded is quite confusing, and I think it would be better if the information in the second column simply ended after the first period. As it stands, the explanation for “key name” seems to suggest that the 255-character limit applies to the entire key path relative to the top-level key. In reality, the limit of 255 (or to be precise, 256) characters applies to the individual name of each registry key, and value names are indeed limited to 16,383 characters. These assumptions are the basis for the entire registry code.
Despite these being fundamental and documented values, it might be surprising that the requirements weren’t correctly verified in the hive loading code until October 2022. Specifically, it was possible to load a hive containing a key with a name of up to 1040 characters. Furthermore, the length of a value’s name wasn’t checked at all, meaning it could consist of up to 65535 characters, which is the maximum value of the uint16 type representing its length. In both cases, it was possible to exceed the theoretical limits set by the documentation by more than four times.
I reported these bugs as part of the CVE-2022-37991 report. On a default Windows installation, I found a way to potentially exploit (or at least trigger a reproducible crash) the missing check for the value name length, but I couldn’t demonstrate the consequences of an overly long key name. Nevertheless, I’m convinced that with a bit more research, one could find an application or driver implementing a registry callback that assumes key names cannot be longer than 255 characters, leading to a buffer overflow or other memory corruption. This example clearly shows that even the official documentation cannot be trusted, and all assumptions, even the most fundamental ones, must be verified directly in the code during vulnerability research.
Creation of stable keys under volatile ones
Another rational behavior of the registry is that it doesn’t allow you to create Stable keys under Volatile parent keys. This makes sense, as stable keys are stored on disk and persist through hive unload and system reboot, whereas volatile keys only exist in memory and vanish when the hive is unloaded. Consequently, a stable key under a volatile one wouldn’t be practical, as its parent would disappear after a restart, severing its path to the registry tree root, causing the stable key to disappear as well. Therefore, under normal conditions, creating such a key is impossible, and any attempts to do so results in the ERROR_CHILD_MUST_BE_VOLATILE error being returned to the caller. While there’s no official mention of this in the documentation (except for a brief description of the error code), Raymond Chen addressed it on his blog, providing at least some documentation of this behavior.
During my research, I discovered two ways to bypass this requirement and create stable keys under volatile ones. These were issues CVE-2023-21748 and CVE-2024-26173, where the first one was related to registry virtualization, and the second to transaction support. Interestingly, in both of these cases, it was clear that a certain invariant in the registry design was being broken, but it was less clear whether this could have any real consequences for system security. After spending some time on analysis, I came to the conclusion that there was at least a theoretical chance of some security impact, due to the fact that security descriptors of volatile keys are not linked together into a global linked list in the same way stable security descriptors are. Long story short, if later in time some other stable keys in the hive started to share the security descriptor of the stable-under-volatile one, then their security would become invalidated and forcibly reset to their parent’s descriptor on the next system reboot, violating the security model of the registry. Microsoft apparently shared my assessment of the situation, as they decided to fix both bugs as part of a security bulletin. Still, this is an interesting illustration of the complexity of the registry – sometimes finding an anomaly in the kernel logic can generate some kind of inconsistent state, but its implications might not be clear without further, detailed analysis.
Arbitrary key existence information leak
If someone were to ask me whether an unprivileged user should be able to check for the existence of a registry key without having any access rights to that key or its parent in a secure operating system, I would say absolutely not. However, this is possible on Windows, because the code responsible for opening keys first performs a full path lookup, and only then checks the access rights. This allows for differentiation between existing keys (return value STATUS_ACCESS_DENIED) and non-existing keys (return value STATUS_OBJECT_NAME_NOT_FOUND).
After discovering this behavior, I decided to report it to Microsoft in December 2023. The vendor’s response was that it is indeed a bug, but its severity is not high enough to be fixed as an official vulnerability. I somewhat understand this interpretation, as the amount of information that can be disclosed in this way is quite low (i.e. limited configuration elements of other users), and fixing the issue would probably involve significant code refactoring and a potential performance decrease. It’s also difficult to say whether this type of boundary is properly defensible, because after one fix it might turn out that there are many other ways to leak this type of information. Therefore, the technique described in my report still works at the time of writing this blog post.
Miscellaneous
In addition to the bug classes mentioned above, there are also many other types of issues that can occur in the registry. I certainly won’t be able to name them all, but briefly, here are a few more primitives that come to mind when I think about registry vulnerabilities:
- Low-severity security bugs: These include local DoS issues such as NULL pointer dereferences, infinite loops, direct KeBugCheckEx calls, as well as classic memory leaks, low-quality out-of-bounds reads, and others. The details of a number of such bugs can be found in the p0tools/WinRegLowSeverityBugs repository on GitHub.
- Real, but unexploitable bugs: These are bugs that are present in the code, but cannot be exploited due to some mitigating factors. Examples include bugs in the CmpComputeComponentHashes and HvCheckBin internal functions.
- Memory management bugs: These bugs are specifically related to the management of hive section views in the context of the Registry process. This especially applies to situations where the hive is loaded from a file on a removable drive, from a remote SMB share, or from a file on a local disk but with unusual semantics (e.g., a placeholder file created through the Cloud Filter API). Two examples of this vulnerability type are CVE-2024-43452 and CVE-2024-49114.
- Unusual primitives: These are various non standard primitives that are simply too difficult to categorize, such as CVE-2024-26177, CVE-2024-26178, WinRegLowSeverityBugs #19, or WinRegLowSeverityBugs #20.
Fuzzing considerations
Due to the Windows Registry’s strictly defined format (regf) and interface (around a dozen specific syscalls that operate on it), automated testing in the form of fuzzing is certainly possible. We are dealing with kernel code here, so it’s not as simple as taking any library that parses a file format and connecting it to a standard fuzzer like AFL++, Honggfuzz, or Jackalope – registry fuzzing requires a bit more work. But, in its simplest form, it could consist of just a few trivial steps: finding an existing regf file, writing a bit-flipping mutator, writing a short harness that loads the hive using RegLoadAppKey, and then running those two programs in an infinite loop and waiting for the system to crash.
It’s hard to argue that this isn’t some form of fuzzing, and in many cases, these kinds of methods are perfectly sufficient for finding plenty of serious vulnerabilities. After all, my entire months-long research project started with this fairly primitive fuzzing, which did more or less what I described above, with just a few additional improvements:
- Fixing the hash in the regf header,
- Performing a few simple operations on the hive, like enumerating subkeys and values,
- Running on multiple machines at once,
- Collecting code coverage information from the Windows kernel.
Despite my best efforts, this type of fuzzing was only able to find one vulnerability (CVE-2022-35768), compared to over 50 that I later discovered manually by analyzing the Windows kernel code myself. This ratio doesn’t speak well for fuzzing, and it stems from the fact that the registry isn’t as simple a target for automated testing as it might seem. On the contrary, each individual element of such fuzzing is quite difficult and requires a large time investment if one wishes to do it effectively. In the following sections, I’ll focus on each of these components (corpus, mutator, harness and bug detection), pointing out what I think could be improved in them compared to the most basic version discussed above.
Initial corpus
The first issue a potential researcher may encounter is gathering an initial corpus of input files. Sure, one can typically find dozens of regf files even on a clean Windows installation, but the problem is that they are all very simple and don’t exhibit characteristics interesting from a fuzzing perspective. In particular:
- All of these hives are generated by the same registry implementation, which means that their state is limited to the set of states produced by Windows, and not the wider set of states accepted by the hive loader.
- The data structures within them are practically never even close to the limits imposed by the format itself, for example:
- The maximum length of key and value names are 256 and 16,383 characters, but most names in standard hives are shorter than 30 characters.
- The maximum nesting depth of the tree is 512 levels, but in most hives, the nesting doesn’t exceed 10 levels.
- The maximum number of keys and values in a hive is limited only by the maximum space of 2 GiB, but standard hives usually include at most a few subkeys and associated values – certainly not the quantities that could trigger any real bugs in the code.
This means that gathering a good initial corpus of hives is very difficult, especially considering that there aren’t many interesting regf hives available on the Internet, either. The other options are as follows: either simply accept the poor starting corpus and hope that these shortcomings will be made up for by a good mutator (see next section), especially if combined with coverage-based fuzzing, or try to generate a better one yourself by writing a generator based on one of the existing interfaces (the kernel registry implementation, the user-mode Offline Registry Library, or some other open-source library). As a last resort, you could also write your own regf file generator from scratch, where you would have full control over every aspect of the format and could introduce any variance at any level of abstraction. The last approach is certainly the most ambitious and time-consuming, but could potentially yield the best results.
Mutator
Overall, the issue with the mutator is very similar to the issue with the initial corpus. In both cases, the goal is to generate the most “interesting” regf files possible, according to some metric. However, in this case, we can no longer ignore the problem and hope for the best. If the mutator doesn’t introduce any high-quality changes to the input file, nothing else will. There is no way around it – we have to figure out how to make our mutator test as much state of the registry implementation as possible.
For simplicity, let’s assume the simplest possible mutator that randomly selects N bits in the input data and flips them, and/or selects some M bytes and replaces them with other random values. Let’s consider for a moment what logical types of changes this approach can introduce to the hive structure:
- Enable or disable some flags, e.g., in the _CM_KEY_NODE.Flags field,
- Change the value of a field indicating the length of an array or list, e.g., _CM_KEY_NODE.NameLength, _CM_KEY_VALUE.DataLength, or a 32-bit field indicating the size of a given cell,
- Slightly change the name of a key or value, or the data in the backing cell of a value,
- Corrupt a value sanitized during hive loading, causing the object to be removed from the hive during the self-healing process,
- Change the value of some cell index, usually to an incorrect value,
- Change/corrupt the binary representation of a security descriptor in some way.
This may seem like a broad range of changes, but in fact, each of them is very local and uncoordinated with other modifications in the file. This can be compared to binary mutation of an XML file – sometimes we may corrupt/remove some critical tag or attribute, or even change some textually encoded number to another valid number – but in general, we should not expect any interesting structural changes to occur, such as changing the order of objects, adding/removing objects, duplicating objects, etc. Hives are very similar in nature. For example, it is possible to set the KEY_SYM_LINK flag in a key node by pure chance, but for this key to actually become a valid symlink, it is also necessary to remove all its current values, and add a new value named “SymbolicLinkValue” of type REG_LINK containing a fully qualified registry path. With a mutator operating on single bits and bytes, the probability of this happening is effectively zero.
In my opinion, a dedicated regf mutator would need to operate simultaneously on four levels of abstraction, in order to be able to create the conditions necessary for triggering most bugs:
- On the high-level structure of a hive, where only logical objects matter: keys, values, security descriptors, and the relationships between them. Mutations could involve adding, removing, copying, moving, and changing the internal properties of these three main object types. These mutations should generally conform to the regf format, but sometimes push the boundaries by testing edge cases like handling long names, a large number of subkeys or values, or a deeply nested tree.
- On the level of specific cell types, which can represent the same information in many different ways. This primarily refers to all kinds of lists that connect higher-level objects, particularly subkey lists (index leaves, fast leaves, hash leaves, root indexes), value lists, and linked lists of security descriptors. Where permitted by the format (or sometimes even in violation of the format), the internal representation of these lists could be changed, and its elements could be rearranged or duplicated.
- On the level of cell and bin layout: taking the entire set of interconnected cells as input, they could be rearranged in different orders, in bins of different sizes, sometimes interspersed with empty (or artificially allocated) cells or bins. This could be used to find vulnerabilities specifically related to hive memory management, and also to potentially facilitate triggering/reproducing hive memory corruption issues more reliably.
- On the level of bits and bytes: although this technique is not very effective on its own, it can complement more intelligent mutations. You never know what additional problems can be revealed through completely random changes that may not have been anticipated when implementing the previous ideas. The only caveat is to be careful with the number of those bit flips, as too many of them could negate the overall improvement achieved through higher-level mutations.
As you can see, developing a good mutator requires some consideration of the hive at many levels, and would likely be a long and tedious process. The question also remains whether the time spent in this way would be worth it compared to the effects that can be achieved through manual code analysis. This is an open question, but as a fan of the registry, I would be thrilled to see an open-source project equivalent to fonttools for regf files, i.e., a library that allows “decompiling” hives into XML (or similar) and enables efficient operation on it. One can only dream… 🙂
Finally, I would like to point out that regf files are not the only type of input for which a dedicated mutator could be created. As I’ve already mentioned before, there are also accompanying .LOG1/.LOG2 and .blf/.regtrans-ms files, responsible for the atomicity of individual registry operations and KTM transactions, respectively. Both types of files may not be as complex as the core hive files, but mutating them might still be worthwhile, especially since some bugs have been historically found in their handling. Additionally, other registry operations performed by the harness could also be treated as part of the input. This would resemble an architecture similar to Syzkaller, and storing registry call sequences as part of the corpus would require writing a special grammar-based mutator, or possibly adapting an existing one.
Harness
While having a good mutator for registry-related files is a great start, the vast majority of potential vulnerabilities do not manifest when loading a malformed hive, but only during further operations on said hive. These bugs are mainly related to some complex and unexpected state that has arisen in the registry, and triggering it usually requires a very specific sequence of system calls. Therefore, a well-constructed harness should support a broad range of registry operations in order to effectively test as many different internal states as possible. In particular, it should:
- Perform all standard operations on keys (opening, creating, deleting, renaming, enumerating, setting properties, querying properties, setting notifications), values (setting, deleting, enumerating, querying data) and security descriptors (querying keys for security descriptors, setting new descriptors). For the best result, it would be preferable to randomize the values of their arguments (to a reasonable extent), as well as the order in which the operations are performed.
- Support a “deferred close” mechanism, i.e. instead of closing key handles immediately, maintain a certain cache of such handles to refer to them at a later point in time. In particular, the idea is to sometimes perform an operation on a key that has been deleted, renamed or had its hive unloaded, in order to trigger potential bugs related to object lifetime or the verification that a given key actually exists prior to performing any action on it.
- Load input hives with different flags. The main point here is to load hives with and without the REG_APP_HIVE flag, as the differences in the treatment of app hives and regular hives are sometimes significant enough to warrant testing both scenarios. Randomizing the states of the other few flags that can take arbitrary values could also yield positive results.
- Support the registry virtualization mechanism, which can consist of several components:
- Periodically enabling and disabling virtualization for the current process using the SetTokenInformation(TokenVirtualizationEnabled) call,
- Setting various virtualization flags for individual keys using the NtSetInformationKey(KeySetVirtualizationInformation) call,
- Creating an additional key structure under the HKU<SID>_ClassesVirtualStore tree to exercise the mechanism of key replication / merging state in “query” type operations (e.g. in enumeration of the values of a virtualized key).
- Use transactions, both KTM and lightweight. In particular, it would be useful to mix non-transactional calls with transactional ones, as well as transactional calls within different transactions. This way, we would be able to the code paths responsible for making sure that no two transactions collide with each other, and that non-transactional operations always roll back the entire transactional state before making any changes to the registry. It would also be beneficial if some of these transactions were committed and some rolled back, to test as much of their implementation as possible.
- Support layered keys. For many registry operations, the layered key implementation is completely different than the standard one, and almost always more complicated. However, adding differencing hive support to the fuzzer wouldn’t be trivial, as it would require additional communication with VRegDriver to load/unload the hive. It would also require making some fundamental decisions: which hive(s) do we overlay our input hive on top of? Should we keep pairs of hives in the corpus and overlay them one on top of the other, in order to control the properties of all the keys on the layered key stack? Do we limit ourselves to a key stack of two elements, or create more complicated stacks consisting of three or more hives? These are all open questions to which I don’t know the answer, but I am sure that implementing some form of layered key support would positively affect the number of vulnerabilities that could be found this way.
- Potentially support multi-threading and execute the harness logic in multiple threads at once, allowing it to trigger potential race conditions. The downside of this idea is that unless we run the fuzzing in some special environment, it would probably be non-deterministic, making timing-related bugs difficult to reproduce.
The final consideration for harness development is the prevalence of registry issues caused by improper error handling, particularly cell allocator out-of-memory errors. A potential harness feature could be to artificially trigger these circumstances, perhaps by aggressively filling almost all of the 2 GiB stable/volatile space, causing HvAllocateCell/HvReallocateCell functions to fail. However, this approach would waste significant disk space and memory, and substantially slow down fuzzing, so the net benefit is unclear. Alternative options include hooking the allocator functions to make them fail for a specific fraction of requests (e.g., using DTrace), or applying a runtime kernel modification to reduce the maximum hive space size from 2 GiB to some smaller value (e.g., 16 MiB). These ideas are purely theoretical and would require further testing.
Bug detection
Alongside a good initial corpus, mutator and harness, the fourth and final pillar of an effective fuzzing session is bug detection. After all, what good is it to generate an interesting sample and trigger a problem with a series of complicated calls, if we don’t even notice the bug occurring? In typical user-mode fuzzing, bug detection is assisted by tools such as AddressSanitizer, which are integrated into the build process and add extra instrumentation to the binary to enable the detection of all invalid memory references taking place in the code. In the case of the Windows kernel, a similar role is played by the Special Pool, which isolates individual allocations on kernel pools to maximize the probability of a crash when an out-of-bounds access/use-after-free condition occurs. Additionally, it may also be beneficial to enable the Low Resources Simulation mechanism, which can cause some pool allocations to fail and thus potentially help in triggering bugs related to handling OOM conditions.
The challenge with the registry lies in the fact that most bugs don’t stem from memory corruption within the kernel pools. Typically, we’re dealing with either hive-based memory corruption or its early stage—an inconsistent state within the registry that violates a crucial invariant. Reaching memory corruption in such a scenario necessitates additional steps from an attacker. For instance, consider a situation where the reference count of a security descriptor is decremented without removing a reference to it in a key node. To trigger a system bugcheck, one would need to remove all other references to that security descriptor (e.g., by deleting keys), overwrite it with different data (e.g., by setting a value), and then perform an operation on it or one of its adjacent descriptors that would lead to a system crash. Each extra step significantly decreases the likelihood of achieving the desired state. The fact that cells have their own allocator further hinders fuzzing, as there’s no equivalent of the Special Pool available for it.
Here are a few ideas for addressing the problem, some more realistic than others:
- If we had a special library capable of breaking down regf files at various levels of abstraction, we could have the mutator create the input hive in a way that maximizes the chances of a crash if a bug occurs during a cell operation. For example, we could assign each key a separate security descriptor with refcount=1 (which should make triggering UAFs easier) and place each cell at the end of a separate bin, followed by another, empty bin. This behavior would be very similar to how the Special Pool works, but at the bin and cell level.
- Again, if we had a good regf file parser, we could open the hive saved on disk after each iteration of the harness and verify its internal consistency. This would allow us to catch inconsistent hive states early, even if they didn’t lead to memory corruption or a system crash in a specific case.
- Possibly, instead of implementing the hive parsing and verification mechanism from scratch, one could try to reuse an existing implementation. In particular, an interesting idea would be to use the self-healing property of the registry. Thanks to this, after each iteration, we could theoretically load the hive once again for a short period of time, unload it, and then compare the “before” and “after” representations to see if the loader fixed any parts of the hive during the loading process. We could potentially also try to use the user-mode offreg.dll library for this purpose, which seems to share much of the hive loading code with the Windows kernel, and which would likely be more efficient to call.
- As part of testing a given hive in a harness, we could periodically fill the entire hive (or at least all its existing bins) with random data to increase the probability of detecting UAFs by overwriting freed objects with incorrect data.
Finally, as an optional step, one could consider implementing checks at the harness level to identify logical issues in registry behavior. For example, after each individual operation, the harness could verify whether the process security token and handle access rights actually allowed it – thereby checking if the kernel correctly performed security access checks. Another idea would be to examine whether all operations within a transaction have been applied correctly during the commit phase. As we can see, there are many potential ideas, but when evaluating their potential usefulness, it is important to focus on the registry behaviors and API contracts that are most relevant to system security.
Conclusion
This concludes our exploration of the Windows Registry’s role in system security and effective vulnerability discovery techniques. In the next post, we‘ll stay on the topic of security, but we’ll shift our focus from discovering bugs to developing specific techniques for exploiting them. We‘ll use case studies of some experimental exploits I wrote during my research to demonstrate their practical security implications. See you then!